/
Squirro 2.1.0 - Release Notes
Squirro 2.1.0 - Release Notes
- Patrice Neff
Owned by Patrice Neff
Released on October 9, 2014.
New Features
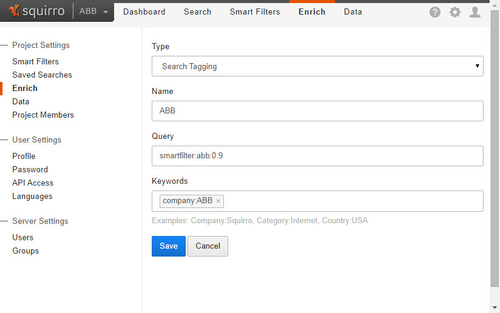
Enrich
The new Enrich menu can be used to configure Search tagging and pipelets.
Any pipelet which is available to a user can be configured as an enrichment. The main pipelets that we currently have readily available:
- Unknown Entity Extraction (TextRazor): Uses the TextRazor API to do natural language parsing of the text and extract keywords.
- Known Entity Extraction: This uses Squirro's own technology to extract keywords from text. Those keywords are imported from the customer's data set, for example a list of suppliers or customers. Talk to your contact at Squirro to make use of this new feature. This will become a self-service offering at a future point in time.
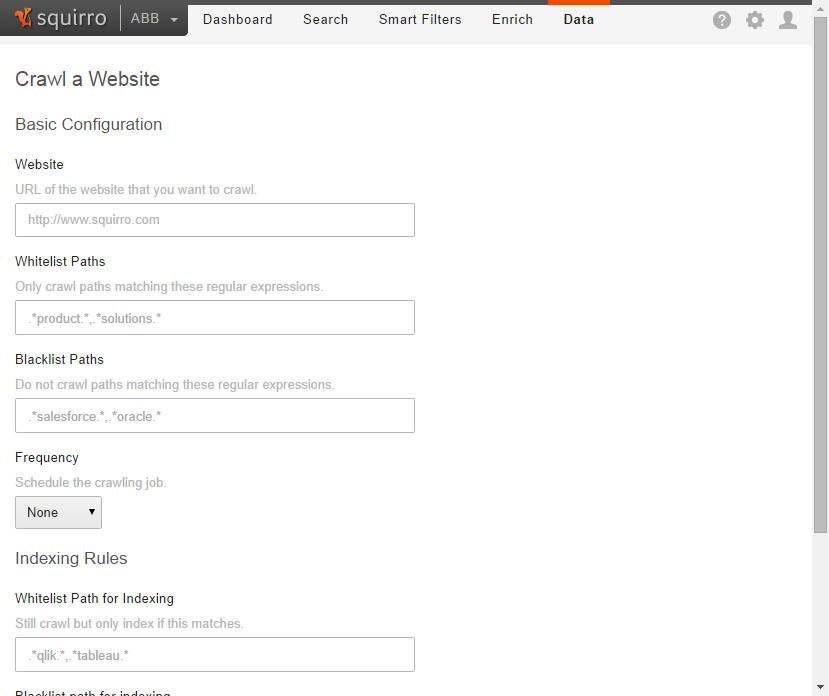
Web Site Crawler
The Web site crawler data source is now readily available in the Add Data menu. Setting up such a crawl can take a few tries to get the white- and blacklists right. That's why there's a Preview Log available, which shows in detail what's happening behind the scenes based on the configuration.
Improvements
- Improve quality of PDF and Office documents text extraction
- Improve display of duplicate items (and renamed from "similar stories" to clarify the scope)
- Some improvements on the embedded PDF viewer
Bug Fixes
- Fix positioning and handling of search results in the result list
- Fix add topic action in the context menu
- Fix handling of new sources in the embedded iFrame
- Fix line charts on the "source" keyword
- Fix reset password action in an embedded dashboard