Pipelets are plugins to the Squirro pipeline, used to customize the data processing.
Table of Contents
Overview
Items that are processed by Squirro go through a pipeline process before they are indexed. In that process a number of built-in enrichments are executed. On top of that, custom enrichment steps can be inserted in the form of pipelets. These pipelets are written in the Python programming language. Pipelets can be uploaded to the Squirro server and then be configured in the user interface (Enrichments tab) or through the API.
This reference documentation covers the basic workflow of working with pipelets and the interface that pipelets need to implement.

Writing Pipelets
Pipelets are written in Python. They need to inherit from the squirro.sdk.PipeletV1 class and implement the consume method. The simplest possible pipelet looks like this:
from squirro.sdk import PipeletV1
class NoopPipelet(PipeletV1):
def consume(self, item):
return item
As it name says it does nothing but return the item unchanged.
The item is a Python dict type and can be modified before it is returned. The available item fields are documented in the Item Format reference. The following example illustrates modifying an item:
from squirro.sdk import PipeletV1
class ModifyTitlePipelet(PipeletV1):
def consume(self, item):
item['title'] = item.get('title', '') + ' - Hello, World!'
return item
This pipelet will modify each item it processes, appending the string "Hello, World!" to the title.
Returning multiple items
The pipelet is always called for each item individually. But in some use cases the pipelet should not just return one item but multiple ones. In those cases use the Python yield statement to return each individual item. For example:
from squirro.sdk import PipeletV1
class ExtendTitlePipelet(PipeletV1):
def consume(self, item):
for i in range(10):
new_item = dict(item)
new_item['title'] = '{0} ({1})'.format(item.get('title', ''), i)
yield new_item
Dependencies
Pipelets are limited in what you can do. For example the print statement is disallowed and you can not import any external libraries except squirro.sdk. If you do need access to external libraries, you need to use the @require decorator. For example to log some output:
from squirro.sdk import PipeletV1, require
@require('log')
class LoggingPipelet(PipeletV1):
def consume(self, item):
self.log.debug('Processing item: %r', item['id'])
return item
As seen from the example, the @require decorator takes a name of a dependency. That dependency is then made available to the pipelet class.
HTTP requests can be executed by using the requests dependency. The following pipelet shows an example for sentiment detection:
from squirro.sdk import PipeletV1, require
@require('requests')
class SentimentPipelet(PipeletV1):
def consume(self, item):
text_content = ' '.join([item.get('title', ''),
item.get('body', '')])
res = self.requests.post('http://example.com/detect',
data={'text': text_content},
headers={'Accept': 'application/json'})
sentiment = res.json()['sentiment']
item.setdefault('keywords', {})['sentiment'] = [sentiment]
return item
Available Dependencies
The following dependencies can be requested:
| Dependency | Description |
|---|---|
cache | Non-persisted cache. |
log | A logging.Logger instance from Python's standard logging framework. |
requests | Python requests library for to execute HTTP requests. |
Configuration
When adding enrichments in the user interface, the administrator can pass in configuration to the pipelet. For example the title modification pipelet could accept a custom suffix that is to be added to the title.
The configuration for this is provided in as JSON data structure:
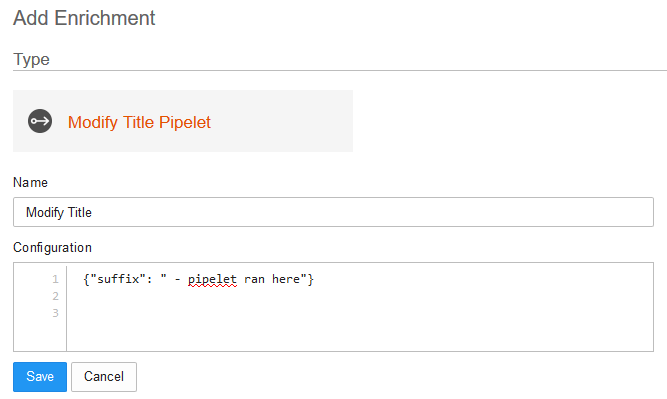
This full data structure is then passed in to the pipelet constructor, where it can be retrieved. Usually it's then simply stored in a object variable so it can be used in the consume method again.
from squirro.sdk import PipeletV1
DEFAULT_SUFFIX = ' - Hello, World!'
class ModifyTitlePipelet(PipeletV1):
def __init__(self, config):
self.config = config
def consume(self, item):
suffix = self.config.get('suffix', DEFAULT_SUFFIX)
item['title'] = item.get('title', '') + suffix
return item
In this example, when the suffix hasn't been provided, the default suffix is used.
Documentation
A pipelet class can be documented using docstrings. The first sentence (separated by period) is used as a summary in the user interface. All the remaining text is used as a description and is often used to document the expected configuration. The description is parsed as Markdown (using the CommonMark dialect). The 60-second overview serves as a good reference.
from squirro.sdk import PipeletV1
DEFAULT_SUFFIX = ' - Hello, World!'
class ModifyTitlePipelet(PipeletV1):
"""Modify item titles.
This appends a suffix to the title of each item. When no suffix is
provided, it appends the default suffix of "- Hello, World!".
Configuration keys:
- suffix: The suffix to add to the title
Example configuration:
{"suffix": " - the pipelet ran"}
"""
def __init__(self, config):
self.config = config
def consume(self, item):
suffix = self.config.get('suffix', DEFAULT_SUFFIX)
item['title'] = item.get('title', '') + suffix
return item
Development Workflow
For developing pipelets, Squirro provides the pipelet command line tool as part of the Toolbox.
Develop
The first step is to create the pipelet. In the following examples the pipelet will have been written to a file called pipelet.py in the current directory.
from squirro.sdk import PipeletV1
class ModifyTitlePipelet(PipeletV1):
def consume(self, item):
item['title'] = item.get('title', '') + ' - Hello, World!'
return item
Validate
On the command line execute the pipelet validate command to verify that there are no errors in the pipelet code. For example this will ensure that no modules are imported that are disallowed from pipelets. See the section on Dependencies for more information.
pipelet validate pipelet.py
Test
The pipelet consume command can be used to simulate pipelet running. For this purpose, the test items should be present in JSON text files on the disk. In the following example there is a item.json file in the current directory with this contents:
{
"title": "Sample",
"id": "first_item"
}
To test the pipelet with this test file, use:
pipelet consume pipelet.py -i item.json
This command will output the items that have been returned by the pipelet:
Loading items...
Loading item.json ...
Loaded.
Consuming item first_item
yielded item
{u'id': u'first_item', u'title': u'Sample - Hello, World!'}
On top of these manual tests, automated tests can be implemented easily using the usual Python tools such as Nose.
Deploy
Once the pipelet is ready, it can be uploaded to the Squirro server. The pipelet upload command achieves that:
pipelet upload --token <your_token> --cluster <cluster> pipelet.py "Hello World"
This will make the pipelet available with the name "Hello World". To update the pipelet code on the server, this command can be re-executed at any time.
To use this in a project, open the Enrichments tab in the Squirro user interface and press "Add Enrichment". In the resulting dialog, the pipelet can be selected in the drop-down menu.

Processing old items
Pipelets are only run for items that are processed in the system after the enrichment has been configured. For information on how to process old items with a pipelet, see Rerunning a Pipelet.
Adding Enrichments
Pipelets are added to a project using the Add Enrichment screen in the user interface.
Alternatively the Enrichments API can also be used to add pipelet enrichments to a project. The following example shows how (using the Python SDK):
# client = SquirroClient(…)
client.create_enrichment(
'Sz7LLLbyTzy_SddblwIxaA',
'pipelet',
'Modify Title',
{'pipelet': 'tenant-example/Modify Title', 'suffix': ' - Title Modified'}
)
This configures a pipelet on project "Sz7LLLbyTzy_SddblwIxaA". The enrichment is called "Modify Title" and uses a pipelet of the same name (use the get_pipelets() call to find the full name in your installation). The config is passed on to the pipelet, so the suffix will be added to the configuration as per the configuration example above.
Also pipelets can be set to execute before a certain pipeline stage. The following example outlines how to do that:
# client = SquirroClient(…)
client.create_enrichment(
'Sz7LLLbyTzy_SddblwIxaA',
'pipelet',
'Modify Title',
{'pipelet': 'tenant-example/Modify Title', 'suffix': ' - Title Modified'},
before='content'
)