The Squirro platform provides insights especially from unstructured data but can also deal with structured data. To achieve this, the data is made available to Squirro through the data import APIs. The data is persisted on the data storage layer and can be consumed with the data access APIs.
At the most fundamental level this can be split into:
Gather - collect data from different systems
Understand - derive information and insights from this data
Act - provide to the users in an easy-to-understand and actionable way

Processing Sections
Zooming in one level, the architecture diagram reveals the more fine-grained sections into which the processing can be split. This also shows how the Squirro AI Studio is used as a foundation for some of these steps.
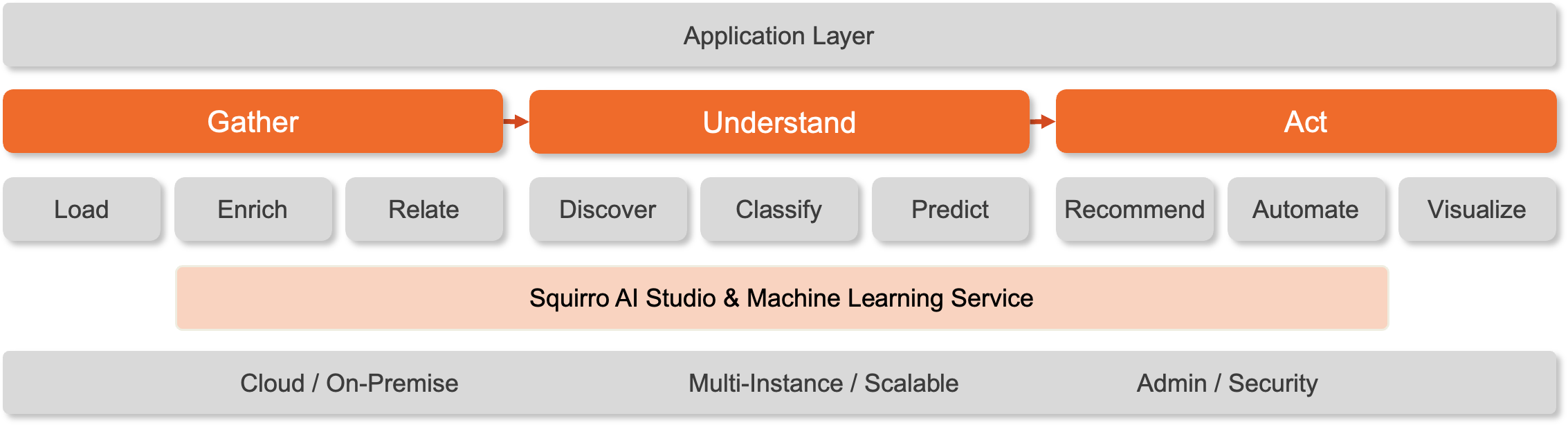
These steps are split into three different areas of the product:
Load - this is the data loading step. The work here is done through built-in as well as custom connectors.
Enrich … Automate - this is handled in the Pipeline. Every item yielded by data loading flows through this pipeline and will eventually get indexed.
Visualize - data is presented to the end users in Dashboards.