The Pipeline Workflows support processing data that have been already processed once.
Every workflow can be used by none, one, or more data sources. The rerun functionality of a workflow uses as input the data from these data sources that have been already retrieved and ingested once.
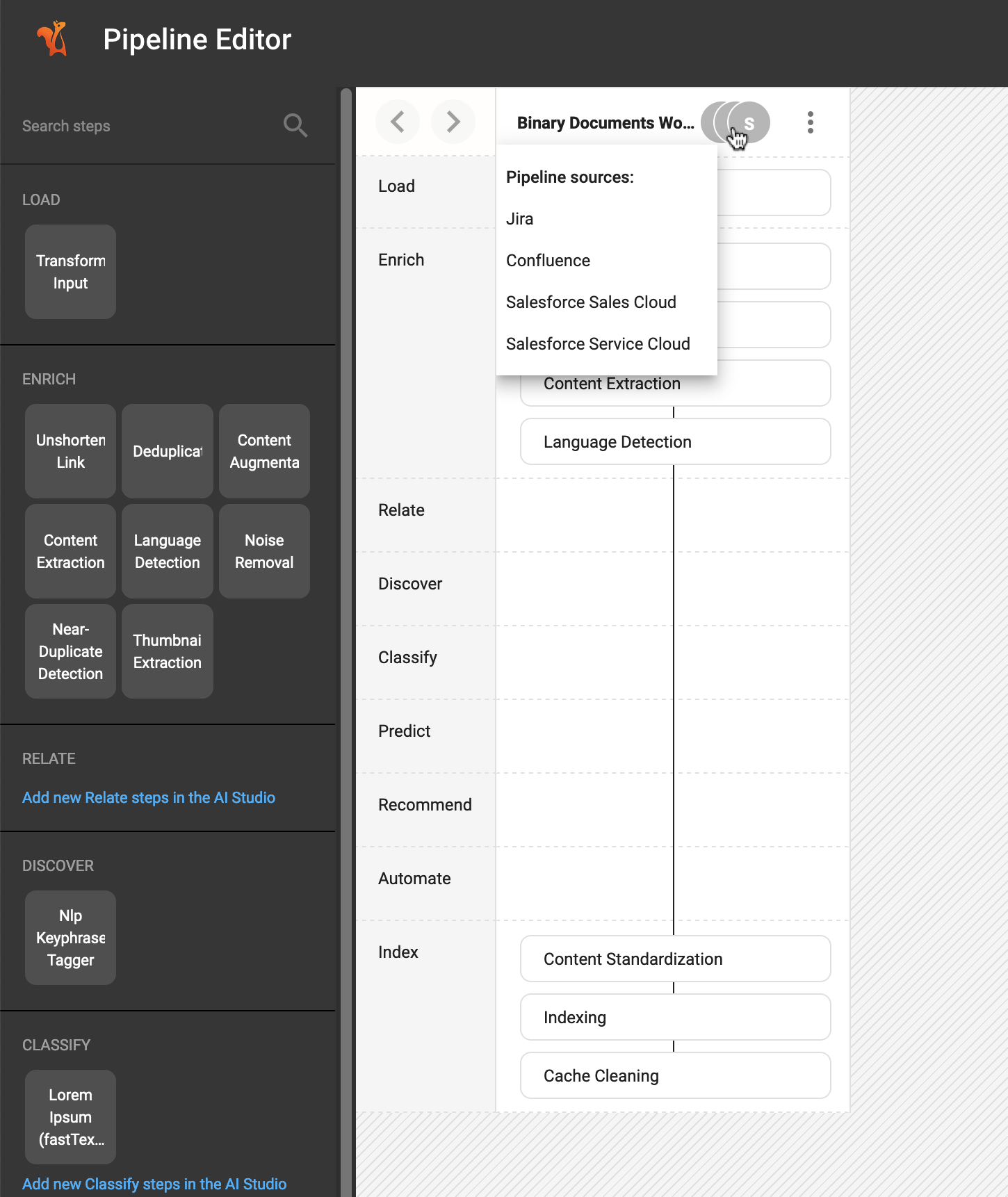
For example, in the above screenshot, there is a workflow for processing Binary Documents and is configured to be used by four data sources. Therefore, the rerun functionality will use as input the processed data of these four sources.
This functionality can be proven useful when you want to modify your workflow, for example, by adding a new step to it or modifying the configuration of an existing step, and would like to execute it against the same set of data and retrieve a potentially different set of Squirro Items which may be more relevant to your needs.
In order to invoke the rerun of a workflow, you may click on its three dots menu, and there you will find the Rerun option.
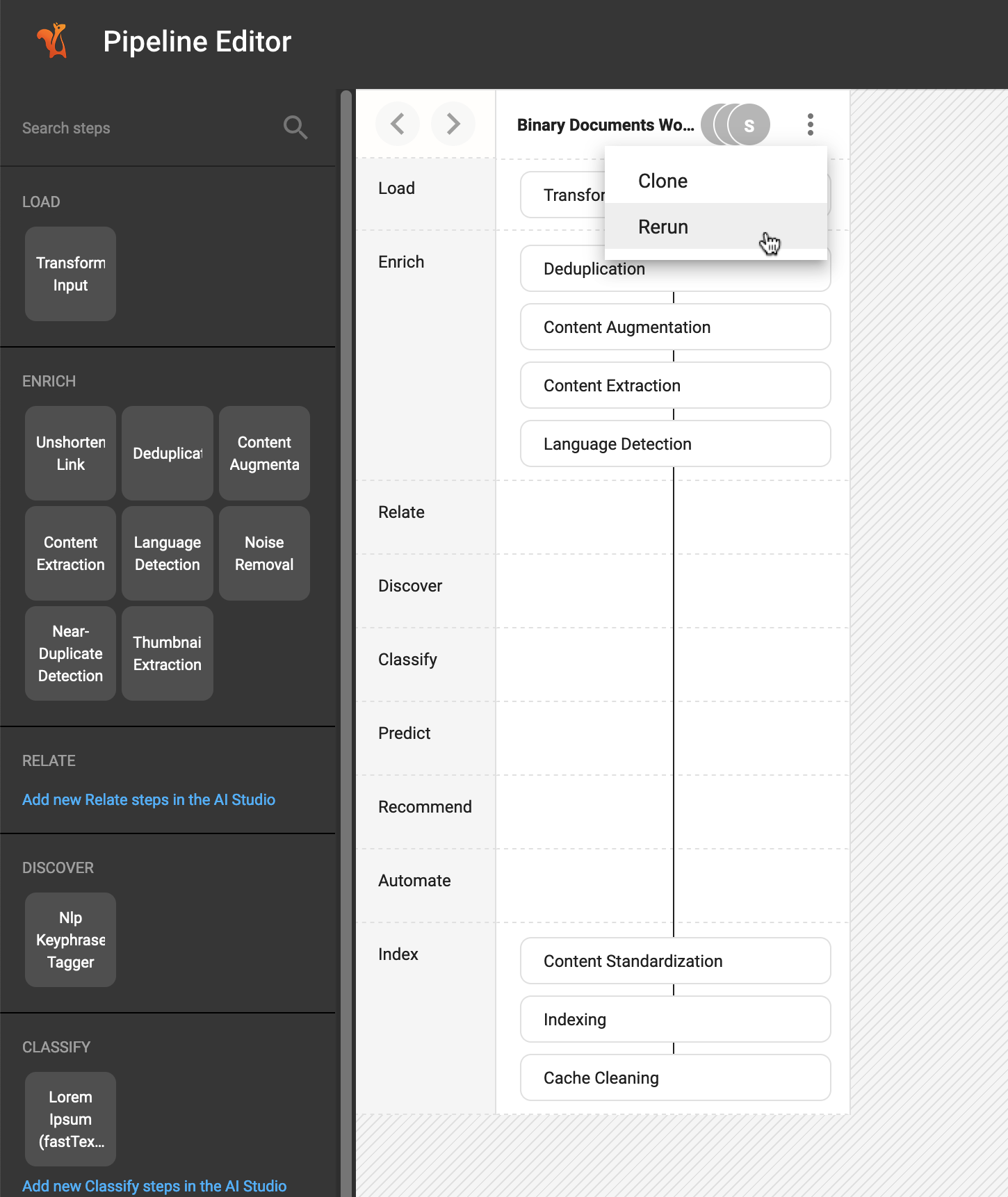
When you click on the Rerun option, a popup window is displayed where you can choose which rerun mode you would like to invoke.

Rerun Modes
There are two rerun modes available:
Rerun from Raw Data
Rerun from Index
Rerun from Raw Data
The rerun from raw data utilizes the data as they were retrieved by a Squirro data loader plugin from the actual data source.
However, please note that this mode is not always available as it requires the storage of the raw data. Also, it is not guaranteed that it will be possible to use all the raw data from the data sources of the pipeline workflow because there is a configurable data retention policy in place which periodically removes these data from the server.
When it is available, it is recommended to be used as it ensures a clean rerun.
Rerun from Index
The rerun from index utilizes the actual Squirro Items which are stored in the storage layer of your Squirro instance.
This mode is always available. However, it is not considered as stable as the other mode, and when the workflow includes a non-idempotent step the resulting Squirro Item will not be the same as the first time that it got ingested, even if the workflow has not changed. As an example, consider a Pipelet which modifies the title of an item by appending an exclamation mark. If we invoke the rerun functionality of a workflow on this item n times, the resulting Squirro Item will contain n exclamation marks in its title.