Executive Summary
The data processing pipeline can be instructed to convert incoming content to HTML.
Table of Contents
Architecture
Data Processing
The content-conversion step is used to convert incoming content to HTML. For supported document formats incoming documents are split into individual pages, each represented as a separate HTML document.
The converted content is used to set the body attribute.
By default the processing step is enabled.
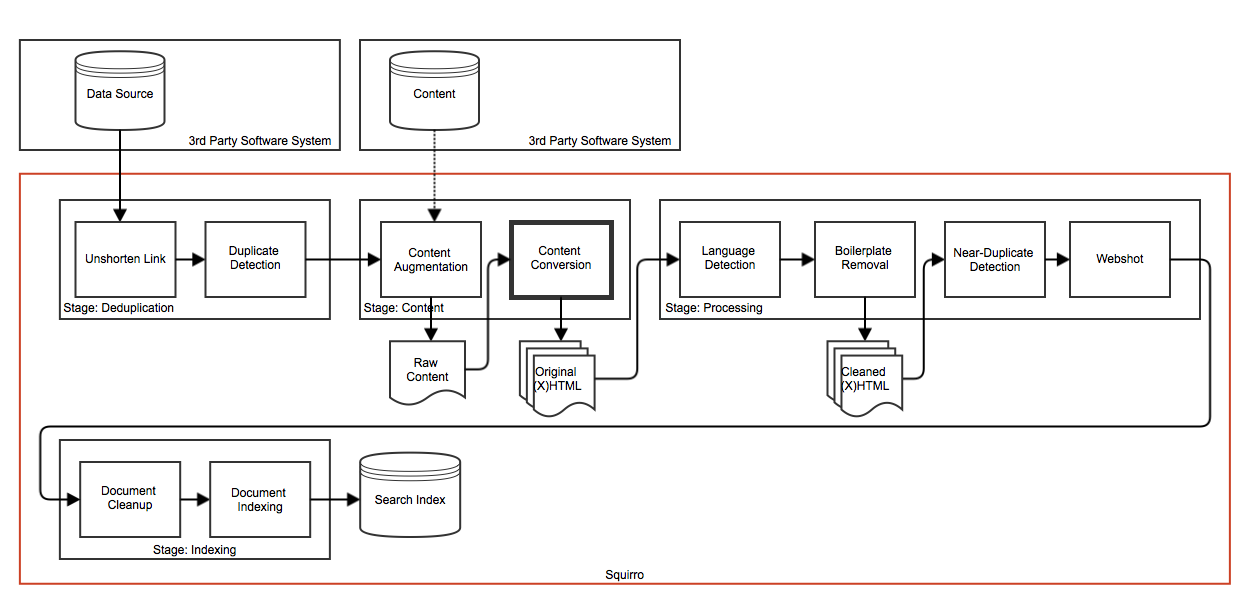
Supported Content MIME Types
The following content MIME types are supported for conversion.
| File Extension | Mime Type | Pages Support | Display Support |
|---|---|---|---|
.pdf | application/pdf | Yes | Full |
.doc | application/msword | No | HTML only |
.docx | application/vnd.openxmlformats-officedocument.wordprocessingml.document | No | HTML only |
.xls | application/vnd.ms-excel | No | HTML only |
.xlsx | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet | No | HTML only |
.ppt | application/vnd.ms-powerpoint | No | HTML only |
.pptx | application/vnd.openxmlformats-officedocument.presentationml.presentation | No | HTML only |
.rtf | text/rtf | No | HTML only |
.odt | application/vnd.oasis.opendocument.text | No | HTML only |
.ods | application/vnd.oasis.opendocument.spreadsheet | No | HTML only |
.odp | application/vnd.oasis.opendocument.presentation | No | HTML only |
.sxw | application/vnd.sun.xml.writer | No | HTML only |
Examples
Python SDK
The following examples reference the Python SDK.
Item Uploader
The following example details how to enable content conversion.
from squirro_client import ItemUploader
# processing config to convert content
processing_config = {
'content-conversion': {
'enabled': True,
},
}
uploader = ItemUploader(..., processing_config=config)
text_body = """
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras aliquet
venenatis blandit. Phasellus dapibus mi eu metus maximus, nec malesuada urna
congue. Vivamus in cursus risus. Sed neque ligula, lobortis in sollicitudin
quis, efficitur eu metus. Pellentesque eu nunc sit amet turpis bibendum
volutpat eu ac ante. Nam posuere eleifend rhoncus. Vivamus purus tellus,
interdum ac semper euismod, scelerisque ut ipsum. Phasellus ut convallis nunc,
quis finibus velit. Class aptent taciti sociosqu ad litora torquent per
conubia nostra, per inceptos himenaeos. Maecenas euismod placerat diam, at
pellentesque quam eleifend ac. Nunc quis est laoreet, hendrerit dui vel,
ornare sem. Integer volutpat ullamcorper orci quis accumsan. Proin
pellentesque vulputate pellentesque. Sed sapien ante, elementum sed lorem vel,
bibendum tristique arcu.
"""
items = [
{
'body': html_body,
'title': 'Item 01',
},
]
uploader.upload(items)
In the example above the processing pipeline is instructed to convert the textual content to HTML and use it as the item body.
Document Uploader
The following example details how to enable content conversion and upload binary documents (original example document can be found here).
from squirro_client import DocumentUploader
uploader = DocumentUploader(...)
# upload a .pdf document which is split into individual pages, the document is
# fully displayed
uploader.upload('connected_campus_using_ews_api.pdf')
# upload a .docx document for which the HTML output will be displayed
uploader.upload('connected_campus_using_ews_api.docx')
uploader.flush()
In the example above the processing pipeline is instructed to convert the binary content to HTML and use it as the item body. The original document display and Squirro document display are depicted below.
| File Extension | Original Document Display | Squirro Document Display | Display Support |
|---|---|---|---|
.pdf | 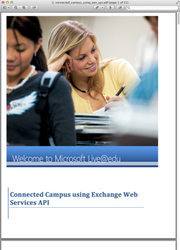  | 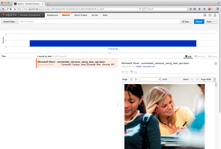 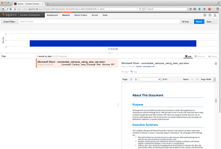 | Full |
.docx |   | 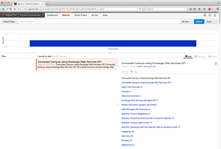  | HTML only |
New Data Source
The following example details how to enable content conversion for a new feed data source.
from squirro_client import SquirroClient
client = SquirroClient(...)
# processing config to convert content
processing_config = {
'content-conversion': {
'enabled': True,
},
}
# source configuration
config = {
'url': 'http://newsfeed.zeit.de/index',
'processing': processing_config
}
# create new source subscription
client.new_subscription(
project_id='...', object_id='default', provider='feed', config=config)
Existing Data Source
The following example details how to enable content conversion for an existing source. Items which have already been processed are not updated.
from squirro_client import SquirroClient
client = SquirroClient(...)
# get existing source configuration (including processing configuration)
source = client.get_project_source(project_id='...', source_id='...')
config = source.get('config', {})
processing_config = config.get('processing_config', {})
# modify processing configuration
processing_config['content-conversion'] = {'enabled': True}
config['processing'] = processing_config
client.modify_project_source(project_id='...', source_id='...', config=config)
In the example above the processing pipeline is instructed to convert content for every new incoming item and use it as the item body.