See Writing a custom data loader for an introduction into how to create these classes.
| Excerpt |
|---|
This page serves as a reference for the SDK, showing the various methods that need to be implemented on a data loader class. |
See also the Data loader plugin boilerplate for a source code template.
Table of Contents
| Table of Contents | ||||
|---|---|---|---|---|
|
Methods
connect (optional)
The connect method is called before loading any of the data.
In the connect method you should perform one-off actions, such as:
- authentication with the API provider
- opening and reading files
- establishing a connection to an external service
- resetting the cache state
You might need some, all or none of the above examples, depending on the nature of your data input.
Return value of the connect method is ignored
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
def connect(self, inc_column=None, max_inc_value=None):
"""Connect to the source."""
if self.args.reset:
self.key_value_cache.clear()
self.key_value_store.clear()
perform_authentication(self.args.username, self.args.password) |
Incremental loading
The parameters inc_column and max_inc_value are used for incremental loading. They contain the name of the column on which incremental loading is done (specified on the command line with --incremental-column) and the maximum value of that column that was received in the previous load. Well-behaved data loader plugins should implement this property, so that only results are returned where inc_column >= max_inc_value. The data loader takes care of all the required book-keeping.
Data loader plugins that do not support incremental loading, should raise an error when this option is specified:
| Code Block | ||
|---|---|---|
| ||
def connect(self, inc_column=None, max_inc_value=None):
if inc_column:
raise ValueError('Incremental loading not supported.') |
Sometimes incremental column is only sensible and supported on one specific column. In that case, it is recommended to enforce that as well:
| Code Block | ||
|---|---|---|
| ||
def connect(self, inc_column=None, max_inc_value=None):
if inc_column and inc_column != 'updated_at':
raise ValueError('Incremental loading is only supported on the updated_at column.') |
disconnect (optional)
Analogous to the connect method, disconnect is always called after finishing all data loading. If an exception is thrown anywhere in the script, disconnect will be called before the script is terminated.
Examples of actions that disconnect might handle are:
- closing the files
- closing any open connections
- saving the state of the most recent load into cache
Return value of the disconnect method is ignored
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
def disconnect(self):
"""Disconnect from the source."""
self.key_value_store['state'] = self.last_known_state
close_remote_conection() |
getJobId (required)
The job identifier is used to distinguish possible multiple data sources, therefore each one should be able to generate a unique job ID.
It is likely that within the same project, you use the same custom data loader, each for a different source, e.g.:
- loading from a different file
- authenticating with an external API with different credentials
- scraping a different website
So it is important that each of these jobs generates a job ID that changes depending on its' custom parameters, e.g. filename, credentials, URL etc.
This is used in order to prevent multiple runs of the same job (only for CLI mode, as jobs run via frontend are managed by the datasource service).
It is good practice to generate a hash from all the custom parameters, as shown in the example (note the use of repr built-in for safe representation of special characters, and finally encoding the string to bytes, as hashlib's update method works on bytes)
Return value of the getJobId method must be a string. Note that if job-id option is provided in the load script, the return value of getJobId is ignored (very special case where you'd provide job-id though).
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
def getJobId(self):
"""
Return a unique string for each different select
:returns a string
"""
# Generate a stable id that changes with the main parameters
m = hashlib.sha1()
m.update(repr(self.args.username).encode('utf8'))
m.update(repr(self.args.website_url).encode('utf8'))
job_id = m.hexdigest()
log.debug("Job ID: %r", job_id)
return job_id |
getArguments (required)
Apart from arguments that you pass to the load script by default (such as source-script, map-title etc.) you can specify custom arguments that allow you to make your loader more re-usable. In particular, you can supply the loader with things like username/password, connection URL or some flags without having to hard-code these.
You can specify a number of arguments, each in the form of a dictionary. Each argument will be converted into a UI component.
Each argument might have multiple properties (keys), being one of the following:
...
How you refer to the argument within the python script, using self.args.<name>
This is also how the arguments are referred to from the load script.
Note: In load script, underscores are replaced by hyphens.
...
The short command line flag for this argument. See example:
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
def getArguments(self):
return [
{
"name": "very_long_argument_name",
"flags": "n"
}
]
|
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
squirro_data_load \
--<some_default_arguments> \
--n 'hello' |
...
The help string. If display_label is not provided, help takes its place as a main label. Otherwise, it serves as a secondary help text in UI.
Example of code and UI representation is shown under the 'required' argument.
...
The short label for this argument shown in the UI.
Set explicitly to 'None' to hide this argument from the UI → that will make it only a CLI argument.
Example of code and UI representation is shown under the 'required' argument.
...
True if this argument is mandatory.
You won't be able to proceed with creation of the load job in the UI if this is not provided.
In the CLI mode, an error will be thrown.
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
def getArguments(self):
"""
Get arguments required by the plugin
"""
return [
{
"name": "my_required_argument",
"display_label": "Required argument",
"required": True,
"help": "This is an example of a required argument"
}
]
|
...
Type to try to convert the value of the argument into.
Basic types are: str, int, float, bool
Special:
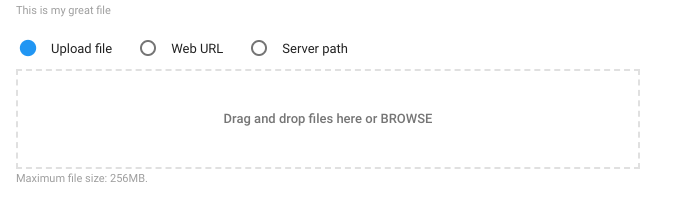
password- which will be used as a string in the load script, but will be interpreted as a password field in the UI (hidden characters)file- allows passing in files. You then read them as:open(self.args.<file_argument>)in the load script. In UI you will see a file dropdown/selector to allow choosing one from your filesystem.code -e.g. SQL statements. A code-editor-like box will show when creating the loader from UI.
The special types eventually end up as type str for use in the Python script. In UI mode however, they have custom appearance as shown in the examples on the right.
...


...
Action to perform when this flag is given.
store is the default and simply allows the usage of the value of the argument within the script
store_true will turn the value of the argument to True if provided, False if not provided. Turned into a checkbox in the UI.
store_false will turn the value of the argument to False if provided, True otherwise. Turned into a checkbox in the UI.
See below examples for clarity
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
def getArguments(self):
return [
{
"name": "my_flag_1",
"action": "store"
},
{
"name": "my_flag_2",
"action": "store_true"
},
{
"name": "my_flag_3",
"action": "store_true"
}
]
|
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
squirro_data_load \
--<some_default_arguments> \
--my_flag_1 'any_string' \
--my_flag_2 |
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
def somewhere_within_the_custom_loader(self):
log.info(self.args.my_flag_1)
// prints 'any_string'
log.info(self.args.my_flag_2)
//prints True
log.info(self.args.my_flag_3)
//prints False, since my_flag_3 was not provided in the load script
|
...

...
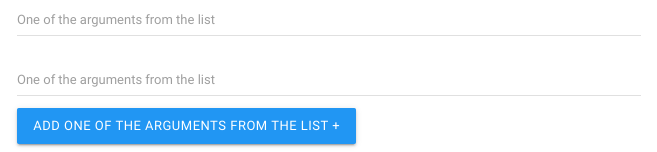
Can be set to "*" if multiple values can be provided for this value."+" can be used if more than one value must be provided.
This is used if you want the user to provide a list of arguments, such as list of IDs, URLs etc.
The resulting value is made available as a list in the source code.
E.g.
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
def getArguments(self):
return [
{
"name": "multi_value_arg",
"nargs": "*"
}
]
|
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
squirro_data_load \
--<some_default_arguments> \
--multi_value_arg 'url_1' 'url_2' 'url_3'
|
...
...

getDataBatch (required)
This method is at the core of data loading. It will return the records from the data source as a dictionary structure. These records are usually referred to as "rows" in the context of the data loader. The data loader will then use this structure and convert it into Squirro items (see Item Format) using the user-provided mapping configuration.
Examples for this method include:
- Iterating through a folder and returning each .txt file as a row
- Connecting to an RSS feed and returning each news feed article as a row
- Connecting to a Redis instance and iterating through keys beginning with "article_" prefix, turning each into a row
(just bear in mind that the connecting part should be done within the connect method)
This method is not expected to return anything. Rather, it will yield items in batches. This is a more efficient way to handle the items, mainly for two reasons:
- The caller of this method cannot handle the upload of say, 1M items at a time. Splitting it in batches will improve the data pipeline efficiency.
- There is no need to construct huge lists of items - instead the process only uses enough memory to hold a batch, thus saving memory.
Batching the rows (as opposed to simply yielding individual rows) makes the process slightly more cumbersome for the data loader plugin, but is essential for performance. By knowing the batch size, the plugin can for example request the correct page size from the database.
It is important to remember that once a batch is yielded, you should clear the old items - otherwise you will return these items twice and also defeat the purpose of efficient processing.
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
def getDataBatch(self, batch_size):
rows = []
for item in original_data_connection:
row = {
'id': item.get('original_id'),
'title': item.get('original_title'),
'body': '\n'.join(item.get('paragraphs')),
'author': item.get('primary_author') or ';'.join(item.get('authors')),
}
rows.append(row)
if len(rows) >= batch_size:
# Yield the items in batches
yield rows
# Remember to clear the old items!
rows = []
# At the end, yield whatever was left
yield rows |
getSchema
getSchema(self)
Returns the header of the data source (list containing the name of the source columns). This is used to decide the valid mapping options and to expand the wildcards inside the facets configuration file.
If this is dynamically decided, it may make sense to return all the keys from the first result from getDataBatch. In the example above (where a custom method getRecords does the actual work), this could be implemented like this:
| Code Block | ||
|---|---|---|
| ||
def getSchema(self):
items = self.getRecords(0, 1)
if items:
return items[0].keys()
else:
return [] |
getDefaultSourceName
This method is used to suggest a default title for the source created in the user interface. If this method has not been implemented, no default title suggestion will be provided. The arguments are available in this method, so this can be used to e.g. suggest a title based on a file name or connection.
For example:
...
| language | py |
|---|
...
This page can now be found at DataSource Class on the Squirro Docs site.