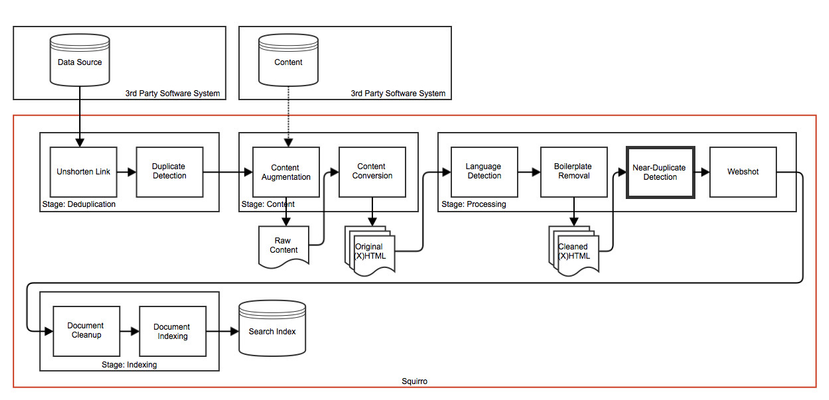
The near duplicate detection enrichment finds previous items that are very similar to the new item and links the items together. This allows to reduce the clutter in search results.
...
Table of Contents
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
The nearduplicate-detection step is used to detect near-duplicate items. Near-duplicates are shown to the user as "duplicates" in the interface. This compares to the deduplication enrichment, which instead discards any new duplicates completely and does not show them to users.
As a consequence the near-duplicate detection enrichment can be more aggressive with its algorithm than the deduplication enrichment. Near-duplicate items are identified based on the title and body field. A locality-sensitive hashing method is used to map similar items to the same hash values.
Tagging
The implementation for near-duplicate detection is based on [1] and consists of the following steps for new incoming items:
- Extract features from the title and body field. This is done by removing HTML tags, applying a lowercase filter, and splitting the corresponding text into tokens.
- The extracted features are used to calculate a 64 bit hash value according to Charikar's simhash technique [2].
- Several permutations of the calculated hash value are computed and stored.
Retrieval
To check whether an incoming item is a near-duplicate of an older item the following steps are necessary:
- Extract features, calculated a 64 bit hash value, and the corresponding permutations as described above.
- For each permutation, retrieve all stored permutations whose top n bit-positions match the top n bit-positions of the permutation.
- For each permutation identified above, calculate the hamming distance and check whether the distance is below a configured threshold k. If that is the case the current item is a near-duplicate candidate and could be folded away.
- For all items found above, check whether they have been created 72 hours before or after the current item. The item created_at field is used for this process. If this requirement is met the current item is folded away under the first matching item.
Configuration
| Field | Default | Description |
|---|---|---|
| cut_off_hours | 72 | Number of hours within which two stories must have been created to be considered near duplicates. |
Examples
These examples use the Python SDK.
Item Uploader
The following example details how to enable near-duplicate detection for a item upload.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import ItemUploader
# processing config to disable near-duplicate detection
processing_config = {
'nearduplicate-detection': {
'enabled': True,
},
}
uploader = ItemUploader(…, processing_config=processing_config)
# item with a link attribute
items = [
...
]
uploader.upload(items) |
New Data Source
The following example details how to disable near-duplicate detection for a new feed data source.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# processing config to disable near-duplicate detection
processing_config = {
'nearduplicate-detection': {
'enabled': False,
},
}
# source configuration
config = {
'processing': processing_config,
'url': 'http://newsfeed.zeit.de/index',
}
# create new source subscription
client.new_subscription(
project_id='…', object_id='default', provider='feed', config=config) |
Existing Data Source
The following example details how to disable near-duplicate detection for an existing source. Items which have already been processed are not updated.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# get existing source configuration (including processing configuration)
source = client.get_subscription(project_id='…', object_id='…', subscription_id='…')
config = source.get('config', {})
processing_config = config.get('processing_config', {})
# modify processing configuration
processing_config['nearduplicate-detection'] = {'enabled': False}
config['processing'] = processing_config
client.modify_subscription(project_id='…', object_id='…', subscription_id='…', config=config) |
References
...
This page can now be found at Near Duplicate Detection on the Squirro Docs site.