The duplicate detection enrichment prevents duplication of items. Items that it has already seen are rejected and not indexed.
| Enrichment name | deduplication |
|---|---|
| Stage | deduplication |
| Enabled by default | Yes |
Table of Contents
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
The deduplication step is used to detect duplicate items. Duplicates are discarded and not shown to the user in the interface.
Duplicate handling has two parts. First there is the actual detection of duplicates. Second is the action executed once a duplicate is detected. The executed actions are specified using a policy.
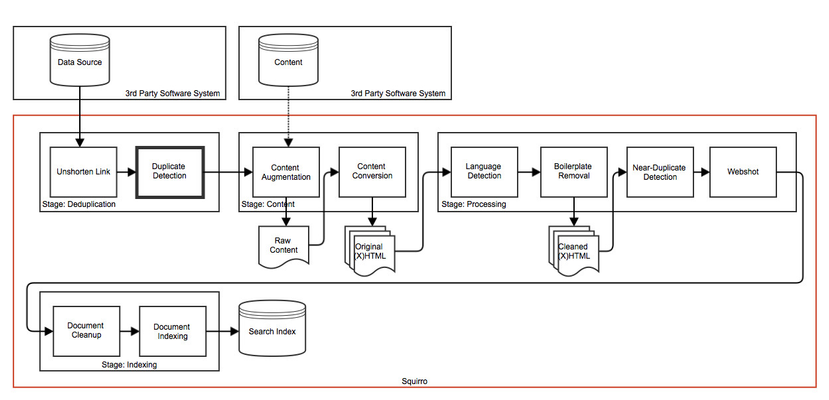
Detection
The detection logic consults the index to find any items with the same properties (see Item Format) as the current item. The item properties for this lookup operation are configurable.
Unless a data source is considerate private (which is the case for sources created by the ItemUploader or DocumentUploader clients from the Python SDK), all sources of a project are included in the lookup. For private sources only the one source is used for the lookup. This behavior prevents data leakage between private and non-private sources.
Policy
If a duplicate item is detected a policy specifies which action is executed. The following table lists available policies and describes the executed action in detail.
| Policy | Default | Description |
|---|---|---|
associate | Default policy for sources configured in the /wiki/spaces/KB/pages/2949421 user interface. | The item that is already in the Squirro index gets the additional source_id in its list of sources and the incoming item is discarded. |
replace | Default policy for sources created by the ItemUploader or DocumentUploader clients from the Python SDK. | The existing item in Squirro is deleted and the incoming item is processed as is. This is mostly used for sources which deliver growing documents like support cases which are amended by additional comments. |
update | - | The existing item in Squirro is updated with all the properties present in the incoming item. Individual properties are replaced (e.g. existing |
Configuration
| Field | Default | Description | |||||
|---|---|---|---|---|---|---|---|
| deduplication_fields |
| Which properties (see Item Format) to consider when searching for duplicates. Each sub-list is looked for individually and the lookup operations stops as soon as a match is found. If a sub-list contains more than one property, all of those properties need to match for an item to be considered a duplicate. | |||||
| policy | associate | The policy decides which action is executed. See above for a table of available policies. | |||||
| provider_support | twitter | Comma-separated list of providers that have support for comments. For providers that support comments, all new comments are merged into the existing item. |
Examples
The following examples all use the Python SDK to show how the duplicate detection enrichment step can be used.
Item Uploader
The following example details how to update duplicate items.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import ItemUploader
# processing config to update duplicate items
processing_config = {
'deduplication': {
'enabled': True,
'policy': 'update',
'deduplication_fields': [
['external_id'],
['link'],
['title'],
],
},
}
uploader = ItemUploader(…, processing_config=config) |
In the example above the processing pipeline is instructed to update duplicate items based on the external_id, link and title properties individually.
New Data Source
The following example details how to update duplicate items for a new feed data source.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# processing config to update duplicate items
processing_config = {
'deduplication': {
'enabled': True,
'policy': 'update',
'deduplication_fields': [
['external_id'],
['link'],
['title'],
],
},
}
# source configuration
config = {
'url': 'http://newsfeed.zeit.de/index',
'processing': processing_config
}
# create new source subscription
client.new_subscription(
project_id='…', object_id='default', provider='feed', config=config) |
In the example above the processing pipeline is instructed to update duplicate items based on the external_id, link and title properties individually.
Existing Data Source
The following example details how to update duplicate items for an existing source. Items which have already been processed are not updated.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# get existing source configuration (including processing configuration)
source = client.get_subscription(project_id='…', object_id='…', subscription_id='…')
config = source.get('config', {})
processing_config = config.get('processing_config', {})
# modify processing configuration
processing_config['deduplication'] = {
'enabled': True,
'policy': 'update',
'deduplication_fields': [
['external_id'],
['link'],
['title'],
],
}
config['processing'] = processing_config
client.modify_subscription(project_id='…', object_id='…', subscription_id='…', config=config) |
In the example above the processing pipeline is instructed to update duplicate items based on the external_id, link and title properties individuallyThis page can now be found at Duplicate Detection on the Squirro Docs site.