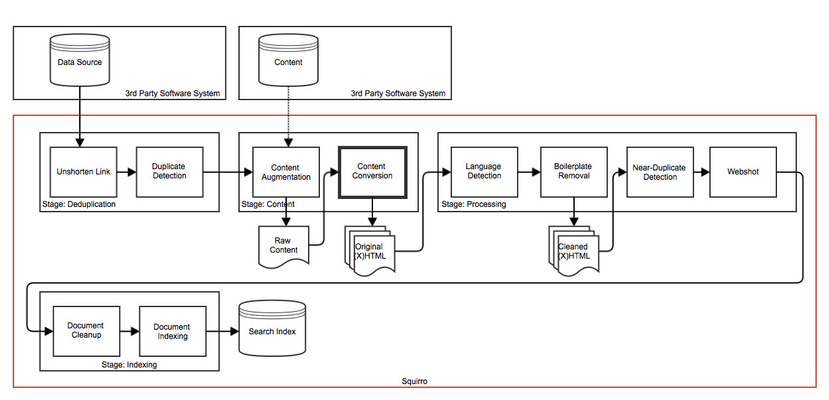
The content conversion enrichment converts incoming content to HTML. This is used to extract textual content from PDF, office and other binary file formats.
| Enrichment name | content-conversion |
|---|---|
| Stage | content |
| Enabled by default | Yes |
Table of Contents
| Table of Contents | ||||
|---|---|---|---|---|
|
Overview
The content-conversion step is used to convert incoming content to HTML. For supported document formats, incoming documents are split into individual pages, each represented as a separate HTML document.
The converted content is used to set the body attribute.
Supported Content MIME Types
The following content MIME types are supported for conversion.
| File Extension | Mime Type | Pages Support | Display Support |
|---|---|---|---|
.pdf | application/pdf | Yes | Full |
.doc | application/msword | No | HTML only |
.docx | application/vnd.openxmlformats-officedocument.wordprocessingml.document | No | HTML only |
.xls | application/vnd.ms-excel | No | HTML only |
.xlsx | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet | No | HTML only |
.ppt | application/vnd.ms-powerpoint | No | HTML only |
.pptx | application/vnd.openxmlformats-officedocument.presentationml.presentation | No | HTML only |
.rtf | text/rtf | No | HTML only |
.odt | application/vnd.oasis.opendocument.text | No | HTML only |
.ods | application/vnd.oasis.opendocument.spreadsheet | No | HTML only |
.odp | application/vnd.oasis.opendocument.presentation | No | HTML only |
.sxw | application/vnd.sun.xml.writer | No | HTML only |
Configuration
There are no configuration options for this enrichment, with the exception of the enabled property to enable and disable it.
Examples
The following examples all use the Python SDK to show how the content conversion enrichment step can be used.
Document Uploader
The following example details how to upload binary documents and use the content conversion step (which is on in this example as its enabled by default).
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import DocumentUploader
uploader = DocumentUploader(…)
# upload a .pdf document which is split into individual pages, the document is
# fully displayed
uploader.upload('connected_campus_using_ews_api.pdf')
# upload a .docx document for which the HTML output will be displayed
uploader.upload('connected_campus_using_ews_api.docx')
uploader.flush() |
In the example above the processing pipeline is instructed to convert the binary content to HTML and use it as the item body. The original document display and Squirro document display are depicted below.
| File Extension | Original Document Display | Squirro Document Display | Display Support |
|---|---|---|---|
.pdf |   |   | Full |
.docx |   |   | HTML only |
New Data Source
The following example details how to disable content conversion for feed data source.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# processing config to convert content
processing_config = {
'content-conversion': {
'enabled': False,
},
}
# source configuration
config = {
'url': 'http://newsfeed.zeit.de/index',
'processing': processing_config
}
# create new source subscription
client.new_subscription(
project_id='…', object_id='default', provider='feed', config=config) |
Existing Data Source
The following example details how to enable content conversion for an existing source. Items which have already been processed are not updated.
| Code Block | ||||
|---|---|---|---|---|
| ||||
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# Get existing source configuration (including processing configuration)
source = client.get_project_source(project_id='…', source_id='…')
config = source.get('config', {})
processing_config = config.get('processing_config', {})
# Modify processing configuration
processing_config['content-conversion'] = {
'enabled': True,
}
config['processing'] = processing_config
client.modify_project_source(project_id='…', source_id='…', config=config) |
In the example above the processing pipeline is instructed to convert content for every new incoming item and use it as the item bodyThis page can now be found at Content Extraction on the Squirro Docs site.