This document aims to outline how Squirro can scale from a single, small development host to a massive multi-node cluster, ingesting millions of documents daily and serving thousand of users.
Table of Contents
| Table of Contents | ||||
|---|---|---|---|---|
|
Basic Concepts
Before going further we should get familiar with the Squirro Architecture. This diagram gives an overview of the key components and technologies Squirro is built with.
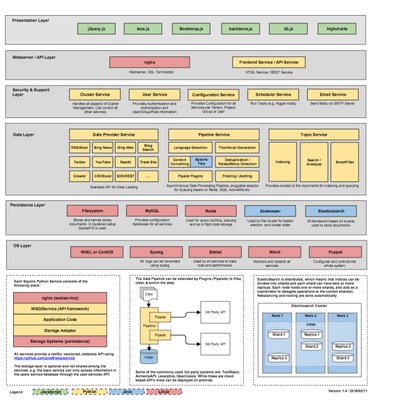
PDF Version:
squirro-architecture-overview-1.4-20160211.pdf
Squirro is built for both the cloud and for on-premise deployments. For this we chose a service oriented approach, where the service is provided not by a few monolithic processes, but a fleet of small, very focused services.
...
Each service of Squirro offers a versioned, restful, language-agnostic (JSON and XML), stateless API. Each service is decoupled and shares nothing with the other services. The only way for these services to communicate is via the API.
This makes Squirro very modular and also simple to scale:
- Each service can be run on as many hosts as needed.
- Load balancing can be done by HTTP load balancers
- Services and hosts can be added / removed from the cluster as needed without any downtime
State and data persistence of Squirro is handled by standard software components that can scale horizontally too. See the sections for Elasticsearch, MySQL, Redis, GlusterFS and Zookeeper below for more details. The Squirro cluster service manages these system, handles failover and takes away a lot of the configuration and management complexity.
Design for Scaling
Scaling Vertically
Squirro can be run on a single host. While we don't recommend this for production environments, its ideal for development and testing environments.
Simply put in the simplest setup with all the components of Squirro deployed:
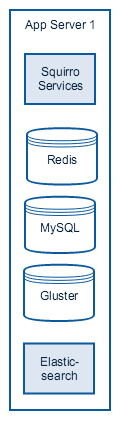
The most crucial component in this setup is RAM. For simple testing purposes, 4 GB is acceptable, if any amount of data will be ingested at least 8 GB is recommended. This setup can be scaled vertically to a certain limit.
These are the major aspects that can be increased:
CPU
The service oriented nature of Squirro benefits from additional CPU cores. While higher CPU frequencies are always beneficial too, we recommend to focus on adding additional CPU cores or threads.
RAM
As more data is ingested and more queries are run in parallel the RAM requirements will increase, especially for Elasticsearch. For production environment we highly recommend to run Elasticsearch on dedicated hosts for this very reason. See below.
Its important to note that there are limits on how much RAM is recommended for Elasticsearch. See https://www.elastic.co/guide/en/elasticsearch/guide/current/_limiting_memory_usage.html for more details.
Storage
Fast, flash based IO is highly recommended and will have a big impact.
| Info | ||
|---|---|---|
| ||
Once a single host is no longer sufficient, an intermediate step before deploying can be to to split Elasticsearch out to a dedicated host. Elasticsearch benefits from fast IO and depends heavily on the filesystem caching. If multiple components compete for RAM and the filesystem cache shrinks, the Elasticsearch performance will drop or will become erratic. |
Scaling Horizontally
Squirro is designed for horizontal scaling. For additional storage needs, resilience and performance additional hosts can be added. In this case, the Squirro cluster and storage nodes are usually split up on different servers.
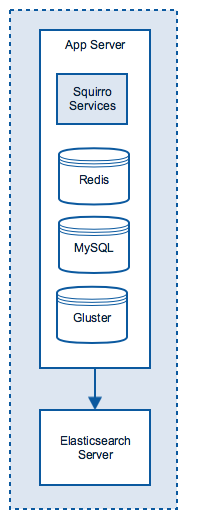
Initial Setup
To prepare for easy scaling, without yet investing in the full server farm, a Squirro setup can be split into the two roles from the beginning.
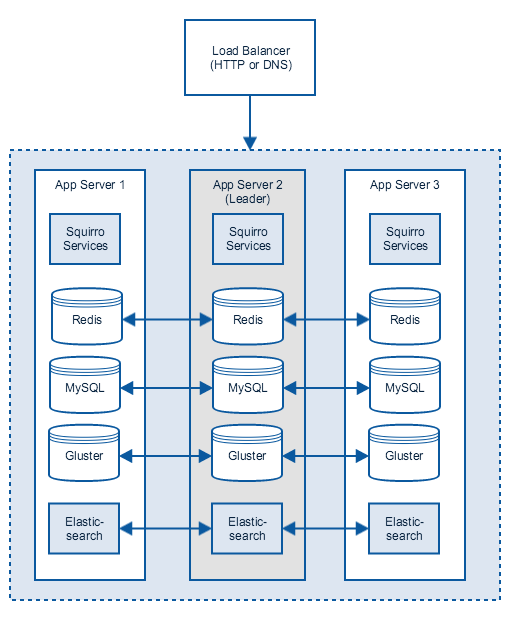
Recommended Cluster Setup
The full horizontal scaling, the recommended setup looks as follows:

The nodes are operated in an active-active setup, the storage as well as the query load is shared across all hosts. Nodes can be added or removed with minimal or no downtime. We recommend a minimum of three nodes so that robust leader election is possible.
The ingested documents are evenly spread across the entire cluster, increasing both the storage capacity as well as lowering the query pressure for each node.
For additional query performance, data can be replicated multiple times inside the Elasticsearch cluster. See the Elasticsearch section below for more details.
In this setup Elasticsearch runs on dedicated hosts for maximum performance. No SAN or NAS is required here, which helps to keep costs low.
Setup without dedicated Elasticsearch nodes
In certain scenarios the main load might not be on Elasticsearch, or high availability is key while the data volume is small. To keep costs lower Elasticsearch can be deployed to the app servers too:
...
| Info | ||
|---|---|---|
| ||
For productive setup factor in plenty of RAM per host. Its crucial that there is enough free RAM so that Elasticsearch can benefit from the filesystem cache. |
Single Node Setup with full Elasticsearch cluster
In scenarios with very high data volume, but simple or few queries and no HA requirement, this setup can scale very well and keep costs low:
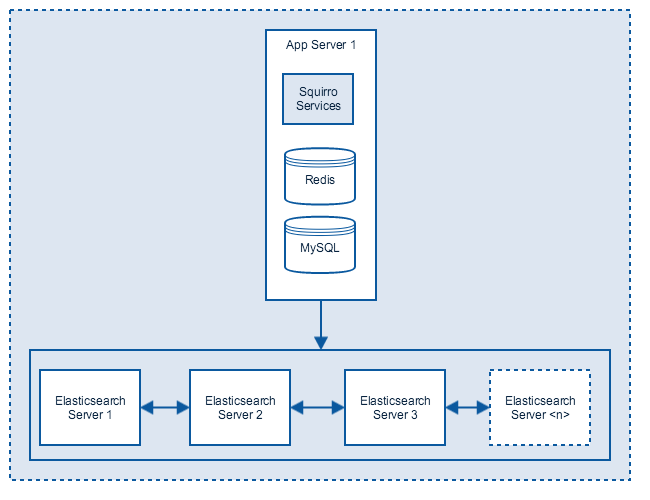
In this example the Squirro node does not offer high availability, but the Elasticsearch cluster still does if replica level is set to > 0.
A setup that fits your needs
Both roles can be scaled independently, e.g. a setup with 3 App Servers and 7 Elasticsearch hosts is possible too, if that fits your needs.
For both roles the same logic applies: Better to have more medium sized hosts, than just a few very big ones.
If you go for high availability, for both roles, start with at least 3 hosts, and once you grow, avoid even numbers of hosts
The ideal solution is always: Start small, measure, adjust.
BCP
See BCP - Business Continuity Planning for more details on how to run Squirro across multiple data centers.
Squirro Components
Elasticsearch
...
| title | What is Elasticsearch? |
|---|
...
Squirro uses Elasticsearch as its primary means to store and query its documents. When you ingest data into Squirro, Elasticsearch is the component that will store the bulk of the data. Unless you index binary documents it is actually the only persistence component that will grow based on the data volume you ingest.
Thanks to Elasticsearch, Squirro can scale to massive sizes with relative ease, but there are still a few things to consider:
- How big is the dataset expected to grow?
- How complex will the data be? (e.g. how many fields with how much variation)
- How many documents will be indexed per day/hour/minute/second?
- How many concurrent users will be querying the system in parallel?
- Will those parallel queries all contain aggregations?
- Is the data time-based? e.g. can data be segmented into time based indexes that can be either discarded after some time has elapsed or can be marked as read-only?
These questions will define how many nodes of Elasticsearch, how many shards and replicas, how much RAM and CPU and what type of storage is required to provide the desired user experience and resilience. Whenever the team at Elasticsearch is asked how a specific setup will perform, then answer is always: It depends! While this can be frustrating it is the honest and correct answer.
While Squirro will take away some of the main concerns, e.g. with its intelligent caching layer, the basic logic still applies with Elasticsearch: Start small within the development environment, load real data, test and measure the performance under as real as possible conditions, and adjust & scale accordingly.
Time Based Indexes
Another important aspect is that in Elasticsearch queries can be run against one or multiple indexes. For the application executing the query this makes no difference. This allows for some really powerful patterns if the data can be expired after a given time or if it will be queried by the end users less frequently.
Here is an example:
Lets suppose we have to index 10 million documents every day and keep the data for 30 days. With a single index, we'd end up with an index with 300 million documents. Using sharding and replicas this is a feasible setup.
Using time based indexes we could instead create a dedicated index every day. e.g. index_2016_02_10 and index_2016_02_11.
Each index will be roughly 10 million documents.
If we want to run a query against all 30 days we simply query against index_* and the result and performance will be about the same as above. If we however know based on the Squirro dashboard that the user only is interested in the last say 24 hours, we can choose to only run the query against one or two of these indexes.
This way the data being queried is lower and the query performance will be far superior and the memory overhead for the concurrent queries far lower.
Further reading
See this excellent document from Elasticsearch about how to design for scaling: Elasticsearch: Designing for Scale
MySQL
| Info | ||
|---|---|---|
| ||
MySQL is an open-source relational database management system (RDBMS); in July 2013, it was the world's second most widely used RDBMS, and the most widely used open-source client–server model RDBMS. ... MySQL is a popular choice of database for use in web applications, and is a central component of the widely used LAMP open-source web application software stack (and other "AMP" stacks). |
The MySQL RDBMS is used by Squirro to store configuration data.
No documents are stored in MySQL, hence it does not have to scale with the data volume ingested into Squirro. We've seen deployments with millions of documents and the MySQL database was less than 10 MB.
The main data stored in MySQL is:
- Users
- Groups
- Roles
- User Sessions / Auth Tokens
- Dashboards
- Smart Filters
- Saved Searches
- Scheduled Tasks / Alerts
Scaling
To achieve high availability and scalability the Squirro cluster service configures MySQL in a Master → Slave replication setup. Each node in the Squirro cluster can contribute a MySQL service to the cluster, and the cluster services uses Zookeeper to automatically elect a leader. All remaining nodes will become followers and replicate the entire database.
Read operations will be handled by all nodes, writes will go to the leader and replicated out to the followers.
There are two main concerns when scaling:
- Number of write operations to the Master node
- Concurrent Open Connections to any of the MySQL nodes. (each connection requires RAM)
In general pressure on MySQL is low and the caching layer and connection pooling improve the scaling capability further.
Redis
...
| title | What is Redis? |
|---|
...
Redis is used by Squirro for queuing, temporary data storage and caching.
Temporary Data Storage
Documents are stored in Redis only "in flight". While documents are processed by the pipeline service a copy is kept in Redis for fast access / update. Once documents exit the pipeline and are persisted in Elasticsearch they get removed from Redis.
Queuing
Redis is the primary queueing backend for the pipeline service. Only document references enter the queue, hence the size of that data is minimal. The queing is abstracted using the Kombu library. Other backends such as in-memory, Amazon SQS, RabbitMQ can be supported too.
Caching
Redis is used by Squirro to provide an intelligent caching layer, both for the queries that are executed against Elasticsearch as well as for all HTTP requests between the various Squirro services. Cache entries can be stored long term, and get evicted intelligently when changes to the underlying data or the configuration occur.
Scaling
To achieve high availability and scalability the Squirro cluster service configures Redis in a Master → Slave replication setup. Each node in the Squirro cluster can contribute a Redis service to the cluster, and the cluster services uses Zookeeper to automatically elect a leader. All remaining nodes will become followers and replicate the entire database.
Read operations will be handled by all nodes, writes will go to the leader and will be replicated out to the followers.
There are two main concerns when scaling:
- Number of write operations to the Master node (but Redis is extremely fast)
- The latency between the master node and the slaves.
- The amount of RAM needed (Redis keeps all data in memory)
GlusterFS
| Info | ||
|---|---|---|
| ||
The GlusterFS architecture aggregates compute, storage, and I/O resources into a global namespace. ... Capacity is scaled by adding additional nodes or adding additional storage to each node. Performance is increased by deploying storage among more nodes. High availability is achieved by replicating data n-way between nodes. |
Uses
- Used to store and replicate all filesystem based documents between all nodes. This data only scales with the data ingested into Squirro if the data contains binary documents and that data is also served by Squirro. Otherwise the data requirement are minimal. See next two points.
- Used to store and replicate all pipeline service plugins (pipelets). Storage need is minimal.
- Used to store and replicate Excel / CSV files uploaded using the Web UI based data loader. Storage need is minimal. Data gets deleted after ingestion is completed.
Alternatives
GlusterFS is the default and built-in option for providing scalable and clustered file storage. It is however only one of multiple options:
- Amazon S3 (and compatible storage solution)
- Network Attached Storage, e.g. NFS
- None: If you don't ingest binary documents, don't need pipelets and don't upload Excel/CSV files using the WebUI, no shared filesystem is required.
Zookeeper
| Info | ||
|---|---|---|
| ||
Apache ZooKeeper is a software project of the Apache Software Foundation, providing an open source distributed configuration service, synchronization service, and naming registry for large distributed systems. ZooKeeper was a sub-project of Hadoop but is now a top-level project in its own right. ZooKeeper's architecture supports high availability through redundant services. |
Zookeeper is used by Squirro for leader election. Its design is perfect for this purpose and helps Squirro detect and handle network segmentation / split brain events.
Scaling Considerations
...
This page can now be found at How Squirro Scales on the Squirro Docs site.