...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
| Excerpt |
|---|
| This page shows a number of examples for using the Data Loader. |
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name mapping ^
--source-type csv ^
--map-title InteractionSubject ^
--map-id InteractionID ^
--map-abstract Notes ^
--map-body InteractionType InternalAttendees NoAtendees ^
--map-created-at Date ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
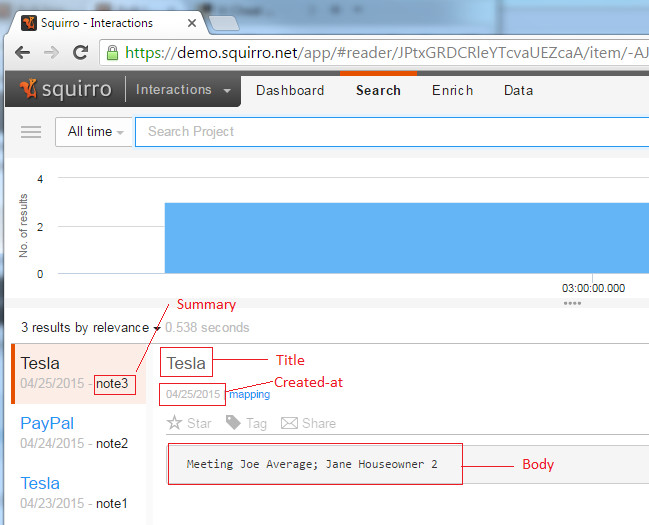
Simple usage and flow control
...
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--db-connection %db_connection% ^
--source-name db_source ^
--source-type database ^
--map-title InteractionSubject ^
--input-file interaction.sql |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
SELECT * FROM Interaction_test WHERE InteractionSubject = 'Tesla' |
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--db-connection %db_connection% ^
--project-id %project_id% ^
--source-name db_source ^
--source-type database ^
--incremental-column Date ^
--map-title InteractionSubject ^
--input-file interaction.sql |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Another row was inserted in the meantime:
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--db-connection %db_connection% ^
--project-id %project_id% ^
--source-name db_source ^
--source-type database ^
--incremental-column Date ^
--reset ^
--map-title InteractionSubject ^
--input-file interaction.sql |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
ItemUploader arguments: object-id, source-id, source-name, bulk-index, bulk-index-add-summary-from-body, batch-size
...
For this example we will use the CSV file again. In order to load the items into an existing source we should use one of the arguments: object-id, source-id or source-name. When using the object-id and source-id arguments, first we need to get these ids from the cluster, using get_user_objects() and get_object_subscriptions(). That is, if we don’t already know them. Or we can use --source-name which we can get in a more simple way, by checking the Data tab in Squirro.
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--object-id 3rd8UDYpQwS8vvFoT3JVWA ^
--source-id yYPR8DA1SPyhTbEXIH0HYw ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv
|
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Usage for bulk-index, bulk-index-add-summary-from-body, batch-size
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name bulk_indexing_source ^
--source-type csv ^
--bulk-index ^
--bulk-index-add-summary-from-body ^
--batch-size 70 ^
--map-title InteractionSubject ^
--map-body Notes ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Parallel executors and source batch size arguments: parallel-uploaders, source-batch-size
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_source ^
--parallel-uploaders 5 ^
--source-batch-size 50 ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Metadata database related arguments
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_source ^
--meta-db-dir %meta_dir% ^
--meta-db-file %meta_file% ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Facets
In this chapter we will describe the use and functionality of the facets configuration file. The facets/keywords are used for filtering data in Squirro.
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_interactions ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv ^
--facets-file config/sample_facets.json |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
You can find the loaded facets in the Data >> Facets tab. You can see below the Facets tab before loading and after:
...
Note that the "input_format_string" should have a Python date format and "format_instr" is just generic date formatting.
 Other uses
Other uses
Other uses of the facets config file are:
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_interactions ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv ^
--facets-file config/sample_facets.json ^
--body-template-file template/template_body_interaction.html |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Note: the name that we use for the facet in the “name” attribute in the facets config file has to be identical with the name from item.keywords tag in the template file
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_interactions ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv ^
--facets-file config/sample_facets.json ^
--body-template-file template/template_body_interaction.html ^
--pipelets-error-behavior error ^
--pipelets-file config/sample_pipelets.json |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
We will use the following pipelets config file:
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--db-connection %db_connection% ^
--log-file log.txt ^
--parallel-uploaders 2 ^
--source-name db_interactions ^
--input-file interaction.sql ^
--source-type database ^
--source-batch-size 500 ^
--incremental-column DateModifiedOn ^
--map-title InteractionSubject ^
--map-id InteractionId ^
--map-created-at DateModifiedOn ^
--map-abstract InteractionType ^
--facets-file config/sample_facets.json ^
--body-template-file template/template_body_interaction.html ^
--pipelets-error-behavior error ^
--pipelets-file config/sample_pipelets.json ^
--meta-db-dir meta ^
--meta-db-file meta_interactions.db |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
The contents of the interactions.sql:
...