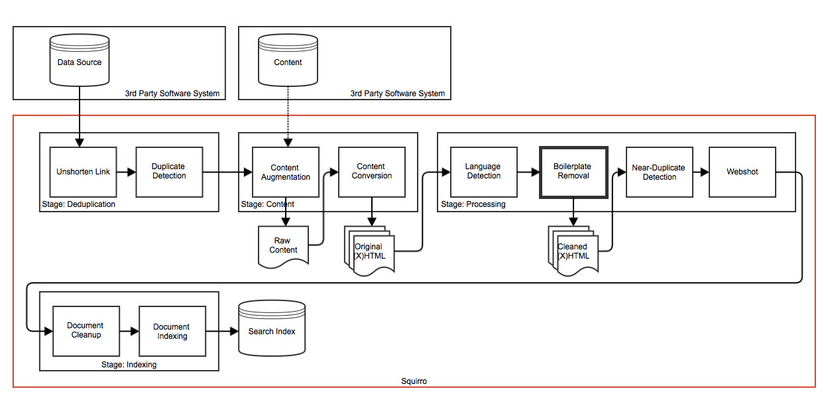
The boilerplate removal enrichment can strip unnecessary content from item bodies. This is useful to extract and index the main content of a document.
| Enrichment name | boilerplate-removal |
|---|---|
| Stage | processing |
| Enabled by default | No |
Table of Contents
Overview
The boilerplate-removal step is used to detect and remove boilerplate content.
Documents are split into individual blocks. These blocks are then classified into two categories: good and bad. Bad blocks correspond to boilerplate content and are removed.
By default the processing step is disabled.
Configuration
| Field | Description |
|---|---|
| classifier | Sets the classifier used for extracting the relevant content. Defaults to the This configuration value is a dictionary with two possible keys:
|
There are two classifiers available, geared towards different use cases.
DefaultClassifier
This is the default classifier which tries to extract as much "good" content as possible.
NewsClassifier
This classifier is geared towards boilerplate detection on news sites. Additional news site specific heuristics are used to remove additional "bad" blocks.
The NewsEndOfContentClassifier sub-classifier is used to detect where the news story ends. This class can be configured using additional rules to tailor the behavior to individual sites. An example processing config:
{
"boilerplate-removal": {
"enabled": true,
"classifier": {
"args": {
"NewsEndOfContentClassifier": {
"rules": {
"en": [
"Share this story"
]
}
}
},
"name": "NewsClassifier"
}
}
}
When end of content classifier finds a text block that starts with any of the given rules, it marks all later blocks as "bad" and does not include them in the final content. The rules are language-specific and the special code "all" can be used to define rules that always apply.
Examples
The following examples all use the Python SDK to show how the boilerplate removal enrichment step can be used.
Item Uploader
The boilerplate removal step can be activated by passing in a processing config to the ItemUploader. The DefaultClassifier is used in this example.
from squirro_client import ItemUploader
# Processing config to detect boilerplate with the default classifier
processing_config = {
'boilerplate-removal': {
'enabled': True,
},
}
uploader = ItemUploader(…, processing_config=config)
html_body = """
<html><body>
<p><a src="http://www.example.com">Boilerplate</a></p>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras aliquet
venenatis blandit. Phasellus dapibus mi eu metus maximus, nec malesuada urna
congue. Vivamus in cursus risus. Sed neque ligula, lobortis in sollicitudin
quis, efficitur eu metus. Pellentesque eu nunc sit amet turpis bibendum
volutpat eu ac ante. Nam posuere eleifend rhoncus. Vivamus purus tellus,
interdum ac semper euismod, scelerisque ut ipsum. Phasellus ut convallis nunc,
quis finibus velit. Class aptent taciti sociosqu ad litora torquent per
conubia nostra, per inceptos himenaeos. Maecenas euismod placerat diam, at
pellentesque quam eleifend ac. Nunc quis est laoreet, hendrerit dui vel,
ornare sem. Integer volutpat ullamcorper orci quis accumsan. Proin
pellentesque vulputate pellentesque. Sed sapien ante, elementum sed lorem vel,
bibendum tristique arcu.</p>
</body></html>
"""
items = [
{
'body': html_body,
'title': 'Item 01',
},
]
uploader.upload(items)
In the example above the processing pipeline is instructed to remove the boilerplate content (i.e. the first <p>...</p> HTML element) from the item body.
New Data Source
The following example details how to enable 3rd party content augmentation and boilerplate removal for a new feed data source. For block classification the NewsClassifier is used to detect boilerplate content. In addition, a custom rule to detect end-of-content blocks is added as well.
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# processing config to fetch 3rd party content and detect boilerplate with the
# news classifier
processing_config = {
'boilerplate-removal': {
'classifier': {
'args': {
'NewsEndOfContentClassifier': {
'rules': {
'de': [
'Mehr zum Thema',
],
},
},
},
'name': 'NewsClassifier',
},
'enabled': True,
},
'content-augmentation': {
'enabled': True,
'fetch_link_content': True,
},
}
# source configuration
config = {
'url': 'http://newsfeed.zeit.de/index',
'processing': processing_config
}
# create new source subscription
client.new_subscription(
project_id='…', object_id='default', provider='feed', config=config)
An example article from the configured source is depicted below. Article content is shown in green and boilerplate content in red. There is also a single end-of-content block shown in blue.
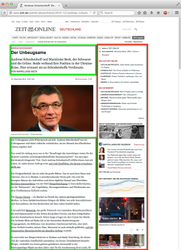 | 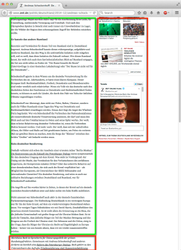 | 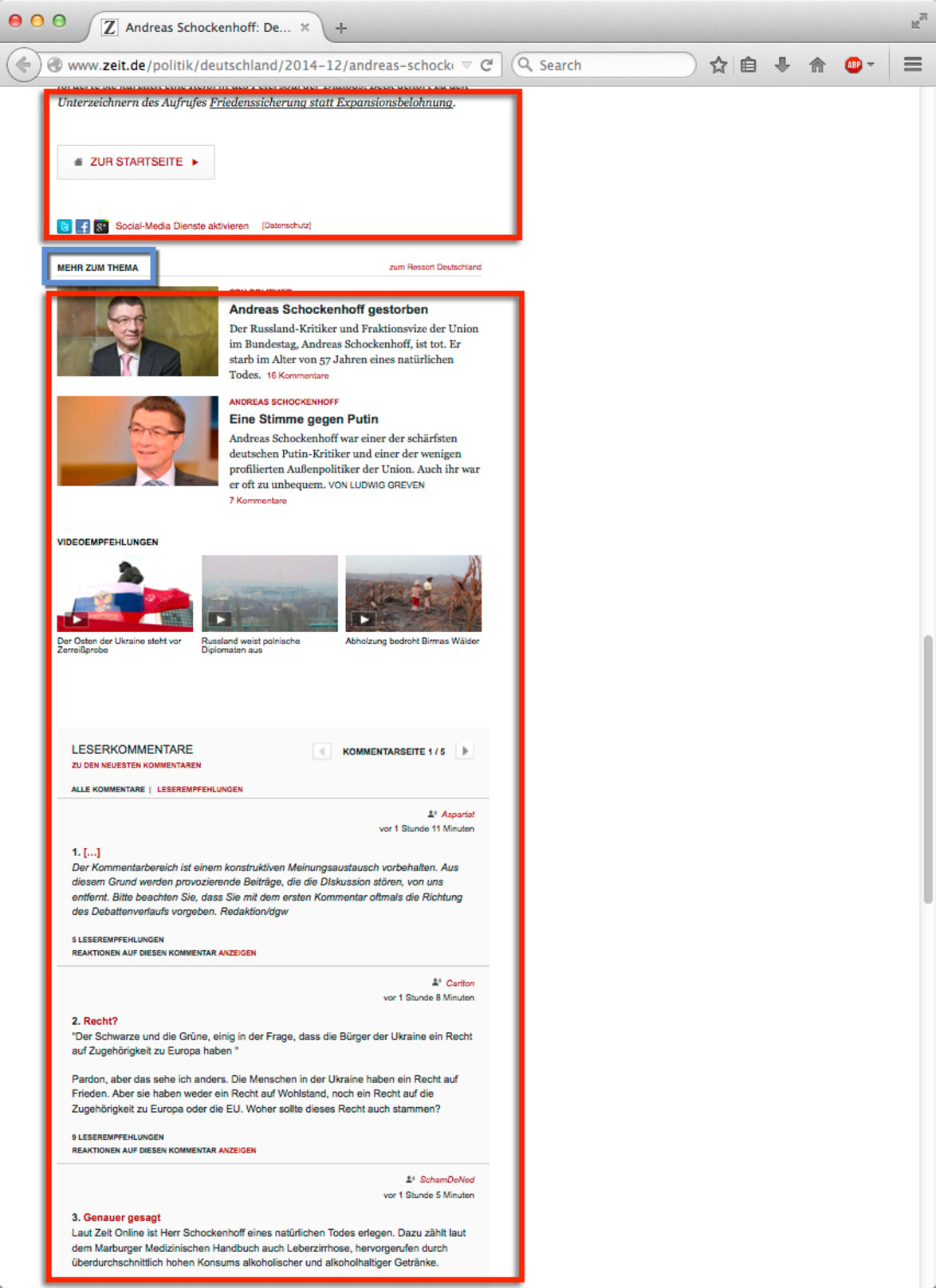 | 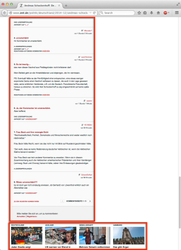 | 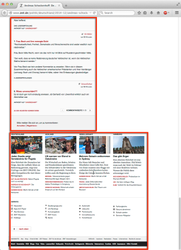 |
Existing Data Source
The following example details how to enable 3rd party content fetching and boilerplate removal for an existing source. Items which have already been processed are not updated.
from squirro_client import SquirroClient
client = SquirroClient(None, None, cluster='https://next.squirro.net/')
client.authenticate(refresh_token='293d…a13b')
# Get existing source configuration (including processing configuration)
source = client.get_subscription(project_id='…', object_id='…', subscription_id='…')
config = source.get('config', {})
processing_config = config.get('processing_config', {})
# Modify processing configuration
processing_config['content-augmentation'] = {
'enabled': True,
'fetch_link_content': True,
}
processing_config['boilerplate-removal'] = {
'enabled': True,
}
config['processing'] = processing_config
client.modify_subscription(project_id='…', object_id='…', subscription_id='…', config=config)
In the example above the processing pipeline is instructed to fetch the content for every new incoming item (from the link attribute) and use it as the item body. After the content is fetched boilerplate is detected and removed.
References
- Christian Kohlschütter, Peter Fankhauser and Wolfgang Nejdl, "Boilerplate Detection using Shallow Text Features", WSDM 2010 -- The Third ACM International Conference on Web Search and Data Mining New York City, NY USA.
- Jan Pomikálek, Removing Boilerplate and Duplicate Content from Web Corpora, Brno, 2011