| Excerpt |
|---|
This tutorial imports an extract of the Panama Papers into Squirro. The focus is especially on how to model and use the facets in this context. |
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--cluster $CLUSTER%CLUSTER% --token $TOKEN%TOKEN% --project-id $PROJECT%PROJECT_IDID% ^
--source-name Entities ^
--bulk-index ^
--source-type csv --source-file Entities.csv ^
--map-id node_id ^
--map-title name |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
This command imports the Entities.csv file into the Squirro project without specifying any facets. This result is not yet very satisfactory:
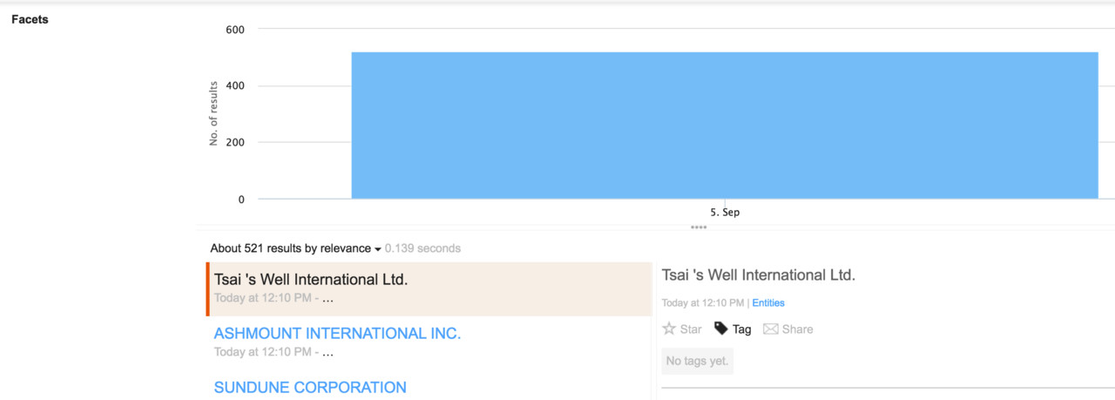
Specify Facets
The next step is to load some of the structured columns as facets.
For this first create a facets.json file in the project folder as follows:
| Code Block | ||||
|---|---|---|---|---|
| ||||
{
"incorporation_date": {
"data_type": "datetime",
"input_format_string": "%d-%b-%Y",
},
"inactivation_date": {
"data_type": "datetime",
"input_format_string": "%d-%b-%Y",
},
"struck_off_date": {
"data_type": "datetime",
"input_format_string": "%d-%b-%Y",
},
"status": {"name": "status"},
"service_provider": {"name": "service_provider"},
"country_codes": {
"name": "country_code",
"delimiter": ";",
},
"countries": {
"name": "country",
"delimiter": ";",
},
"jurisdiction": {"name": "jurisdiction"},
"jurisdiction_description": {"name": "jurisdiction_description"},
"address": {"name": "address"},
} |
This facets configuration file configures the data loader to import the indicated columns into Squirro. A few special notes:
- The three columns
incorporation_date,inactivation_dateandstruck_off_dateare treated as datetime facets. The date format is specified to parse it from the format that's used in the file. - A few columns are simply copied from the CSV to Squirro without any modifications.
- The two columns
country_codesandcountriesare renamed to singular names. Most facets in Squirro use singular names as that makes more sense when selecting a value in the facet dropdown.
Now this facets configuration file can be used in the data loader command (adding one line at the end):
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--cluster $CLUSTER%CLUSTER% --token $TOKEN%TOKEN% --project-id $PROJECT%PROJECT_IDID% ^
--source-name Entities ^
--bulk-index ^
--source-type csv --source-file Entities.csv ^
--map-id node_id ^
--map-title name ^
--facets-file facets.json |
When executing this command, the Squirro project now looks a lot more promising:
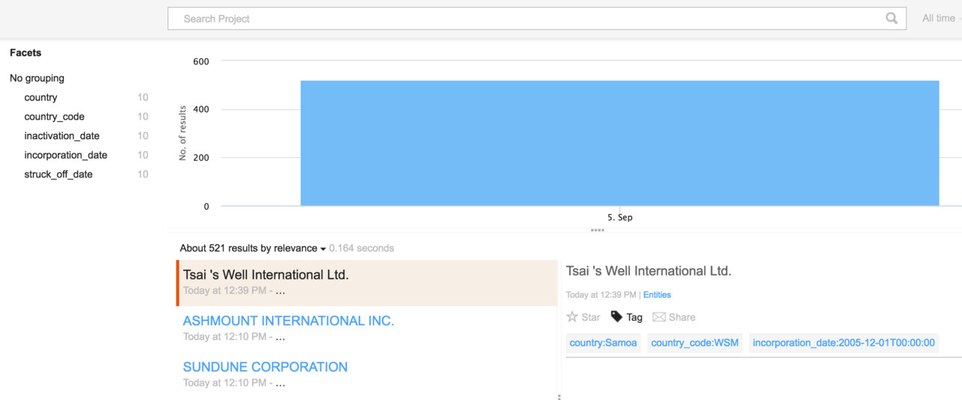
Managing Facets
In the facets management interface (in the Data tab, then Facets) the facets can be customized.
Here you can add some flavor by setting display names and grouping.
The following initial screen shows the facets as they were created based on the facets.json above.
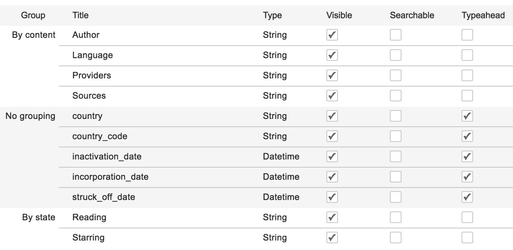
This can be modified facet by facet to result in this screen:
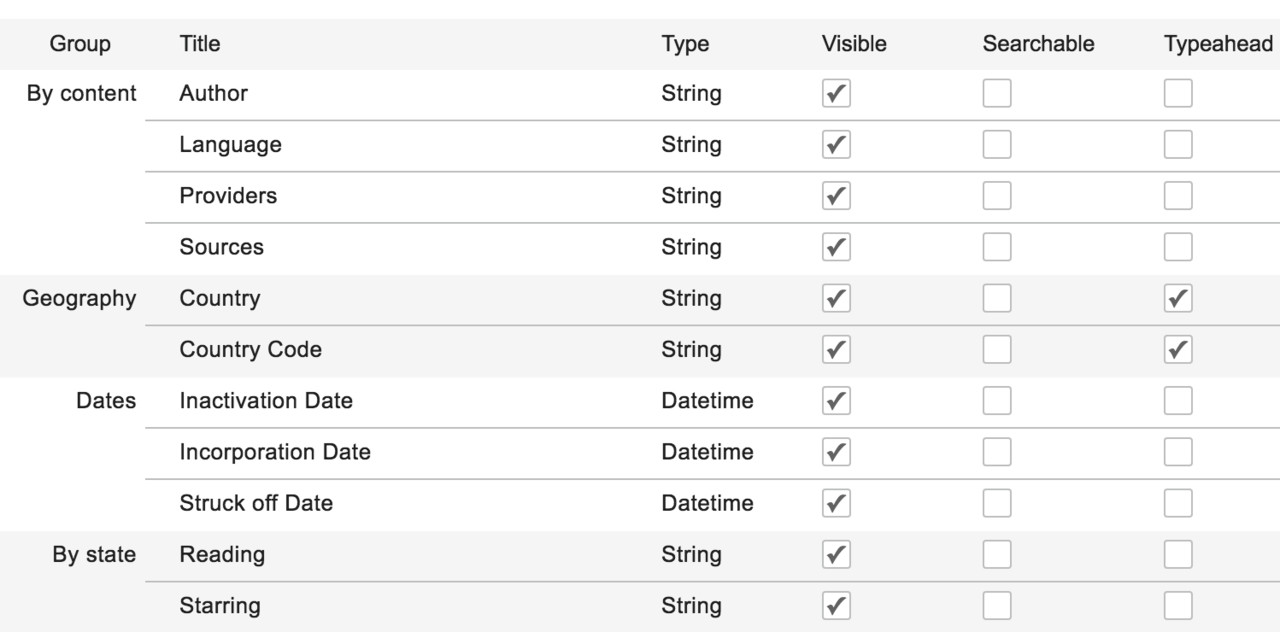
The facets have now been grouped into some custom groups and the date facets are no longer shown in the type-ahead.
Date facets take an additional configuration, which is the format. The following screenshot illustrates this for one example:
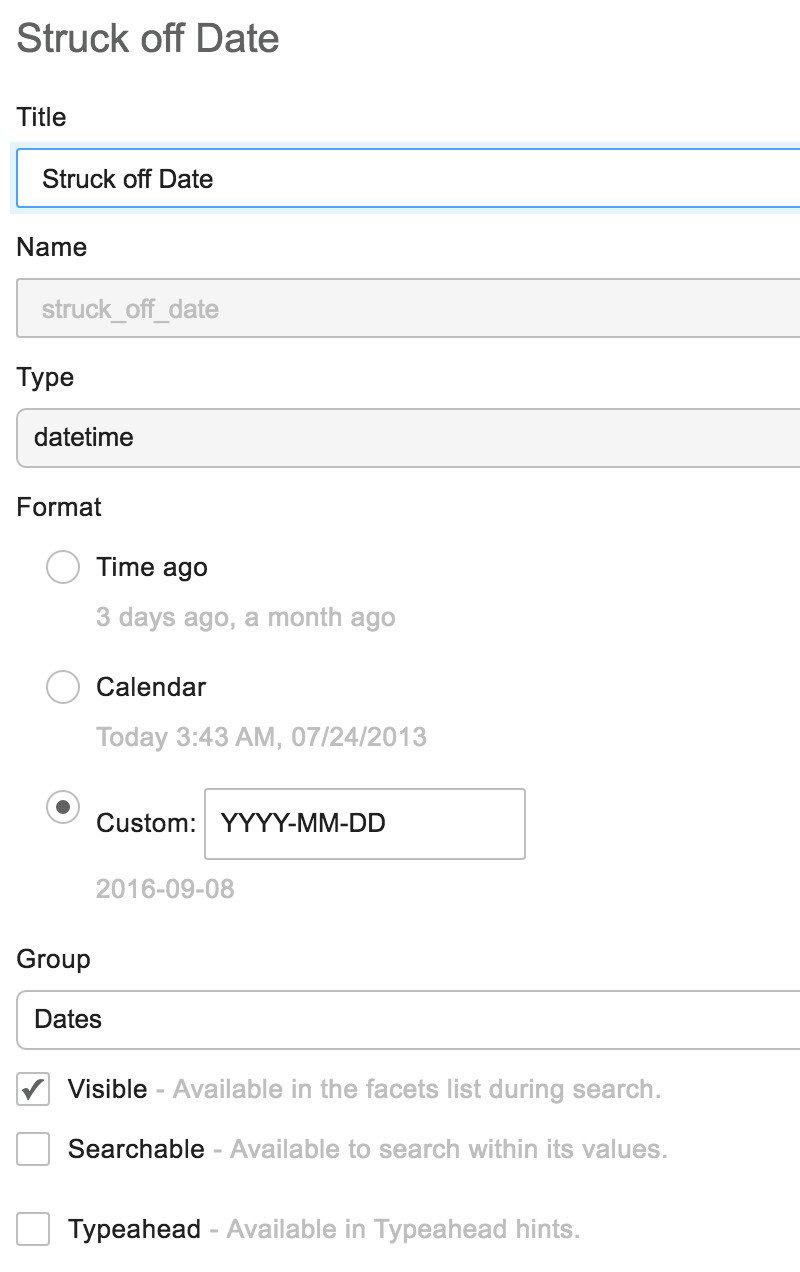
Using the Facets
Navigation
The facets can now be explored in the search user interface. They are nicely grouped and labeled, thus giving a good user experience.
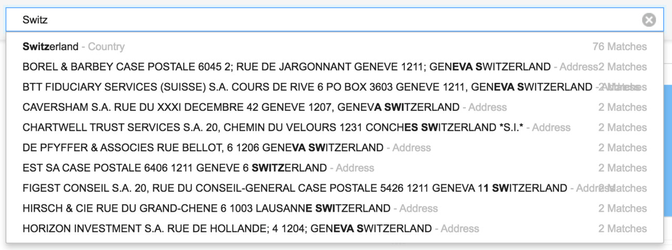
Searching
The facets are shown in the search with type-ahead functionality.
Dashboards
Dashboards can be built using these facets. Just two examples:
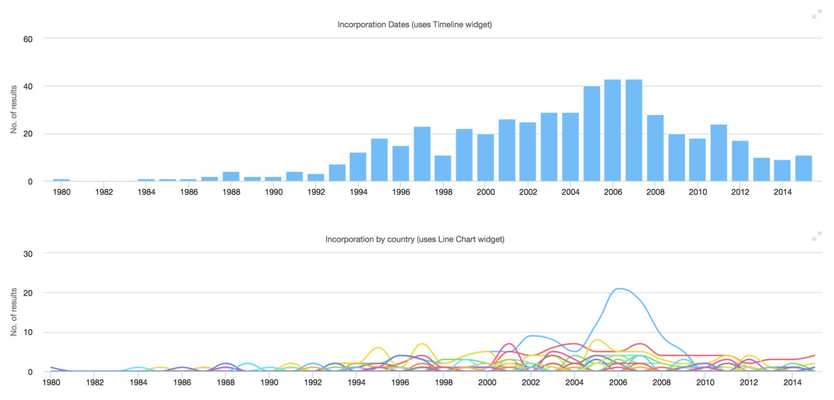
Navigation by country
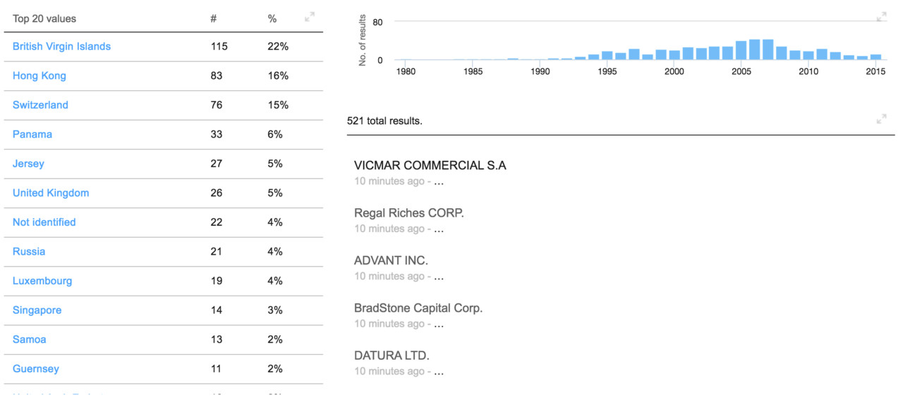
Visualization of incorporation dates
Managing Facets from Data Loader
Using the user interface to manage the facets can quickly become cumbersome for larger data imports. So going forward we'll manage the grouping in the facets.json file. This is how the configuration above can be reflected here.
| Code Block | ||
|---|---|---|
| ||
{
"incorporation_date": {
"display_name": "Incorporation Date",
"group_name": "Dates",
"data_type": "datetime",
"typeahead": false,
"input_format_string": "%d-%b-%Y",
},
"inactivation_date": {
"display_name": "Inactivation Date",
"group_name": "Dates",
"data_type": "datetime",
"typeahead": false,
"input_format_string": "%d-%b-%Y",
},
"struck_off_date": {
"display_name": "Struck-off Date Date",
"group_name": "Dates",
"data_type": "datetime",
"typeahead": false,
"input_format_string": "%d-%b-%Y",
},
"status": {
"display_name": "Status"
"group_name": "Company",
},
"service_provider": {
"display_name": "Service Provider"
"group_name": "Company",
},
"country_codes": {
"name": "country_code",
"display_name": "Country Code",
"group_name": "Geography",
"delimiter": ";",
},
"countries": {
"name": "country",
"display_name": "Country",
"group_name": "Geography",
"delimiter": ";",
},
"jurisdiction": {
"display_name": "Jurisdiction Code",
"group_name": "Geography",
},
"jurisdiction_description": {
"display_name": "Jurisdiction",
"group_name": "Geography",
},
"address": {
"display_name": "Address",
"group_name": "Geography",
},
} |
Note: Observant readers will notice that the facet's date format is not specified. This can not yet be done through the data loader facets.json file.
Run the import with this facets.json file and all the facets will have the right display name, groups, etc.
Searchable Facets
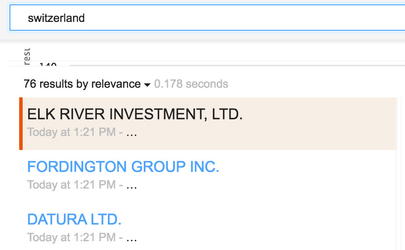
When searching for "Switzerland", the type-ahead will provide some useful output. But when you then ignore the type-ahead and execute the search, no results will come back. That's because none of the facets are searchable and the documents don't contain much data in their titles and bodies.
![]()
To remedy this, we'll change the address facet to be searchable. There are two ways of doing this:
- Use the admin interface and change the address field to searchable.
Use the
facets.jsonfile to declare a field as being searchable.Code Block language js "address": { "display_name": "Address", "group_name": "Geography", "searchable": true, },
Independent of the way you choose, the search will now return the relevant results:
Numeric Facets
The data set does not contain any numeric facets. So let's create one ourselves with a pipelet. We'll calculate the survival time of all companies that have closed and store that as a facet.
Importing
This requires a number of steps:
Create a new facet
survival_timewith the data type int. If this is not done, any int values will be rejected and the indexing will not work. You can do this in the user interface or with the following snippet forfacets.json:Code Block language js "survival_time": { "group_name": "Dates", "data_type": "int", "typeahead": false, },Create a pipelet and store it in
survival_time.py. The following example will get us going:Code Block language py title survival_time.py from squirro.sdk import PipeletV1, require from datetime import datetime DATE_FORMAT = '%Y-%m-%dT%H:%M:%S' @require('log') class SurvivalTimePipelet(PipeletV1): def consume(self, item): kw = item.setdefault('keywords', {}) started = kw.get('incorporation_date') ended = kw.get('inactivation_date') or kw.get('struck_off_date') if not started or not ended: # Ignore this item return item started = datetime.strptime(started[0], DATE_FORMAT) ended = datetime.strptime(ended[0], DATE_FORMAT) if ended <= started: # Protect against invalid ranges return item survival_time = int((ended - started).total_seconds() / 86400) kw['survival_time'] = [survival_time] return itemCreate a
pipelets.jsonconfiguration file to use this pipelet in the data loader:Code Block language js title pipelets.json { "SurvivalTimePipelet": { "file_location": "survival_time.py", "stage": "after templating", } }And finally re-execute the data load step with this command:
Code Block language powershell squirro_data_load -v ^ --cluster $CLUSTER%CLUSTER% --token $TOKEN%TOKEN% --project-id $PROJECT%PROJECT_IDID% ^ --source-name Entities ^ --bulk-index ^ --source-type csv --source-file Entities.csv ^ --map-id node_id ^ --map-title name ^ --map-created-at incorporation_date ^ --facets-file facets.json ^ --pipelets-file pipelets.jsonOnly the last line is new needed - it points the data loader to the
pipelets.jsonfile.
As a bonus we have also added amap-created-atflag, which results in a better output on the search screen.
Using
The data can now be used in a number of ways.
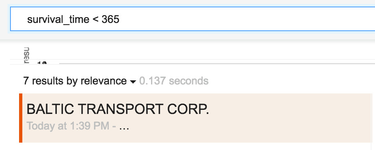
For example which companies closed after less than a year?
Or what is the average survival time of companies by country?

This particular facet is not very useful in the facet drill down. So after using it in the dashboard widget, you may want to hide it by unchecking the "Visible" checkbox.
Conclusion
This concludes the facets tutorial. Based on the Panama Papers export we experimented with the various facet types and how they can be used in the dashboard and search.
To explore the topic further you can dig into Using Facets or Managing Facets. The Data Loader documentation also contains information, especially on the Data Loader Config Reference.