...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
| Excerpt |
|---|
| This page shows a number of examples for using the Data Loader. |
For a full reference documentation please see Data Loader Reference. For a step-by-step tutorial, please refer to the Data Loader Tutorial.
...
| Office Excel | ||
|---|---|---|
|

CSV
The following sample CSV file is used to highlight the Squirro Data Loader capabilities for loading a CSV file. The file contains a single header row and three data rows. The sample file uses the following formatting options:
...
| Code Block | ||
|---|---|---|
| ||
InteractionID,InteractionSubject,InteractionType,Date,Notes,InternalAttendees,NoAtendees,EntittledUsers,DateModifiedOn 100AAA,Tesla,Phone Call,2015-4-23T00:00:00,note1,Joe Average;Jane Houseowner;Elon Musk,3,jdoe;jhouseowner;emusk,4/23/2015 16:58 102BBB,PayPal,Meeting,2015-4-24T00:00:00,note2,Joe Average; Elon Musk,2,jdoe;emusk,4/24/2015 16:58 105CCC,Tesla,Meeting,2015-4-25T00:00:00,note3,Joe Average; Jane Houseowner,2,jdoe;jhouseowner,4/25/2015 16:58 |

Database
The following database sample inserts are used to highlight the capabilities of the Data Loader regarding the load from a database table. The example below is for an SQL Server database.
...
Some (or all) of the source columns can be mapped to the Squirro item fields using the command line arguments. In order for items to be loaded into Squirro, either title or body needs to be specified, all the other fields are optional. Also the --map-flag and --map-id parameters are mutually exclusive.
Field Name | Mandatory | Description | Example |
title | Yes* | Item title. | “Conversation1” |
abstract | No | Item summary. | “Phone call” |
created_at | No | Item creation date and time (see Date and Time). | 02/19/2016 |
id | No | External item identifier. Maximum length is 256 characters. | 100AAA |
body | Yes* | HTML markup with full representation of the item content. | Note1 |
url | No | URL which points to the item origin. | |
file_name | No | LOB file name |
file_mime | No | LOB file mime type |
file_data | No |
file_ compressed | No |
flag | No |
*It is mandatory that at least one of the title or body fields is mapped.
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name mapping ^
--source-type csv ^
--map-title InteractionSubject ^
--map-id InteractionID ^
--map-abstract Notes ^
--map-body InteractionType InternalAttendees NoAtendees ^
--map-created-at Date ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
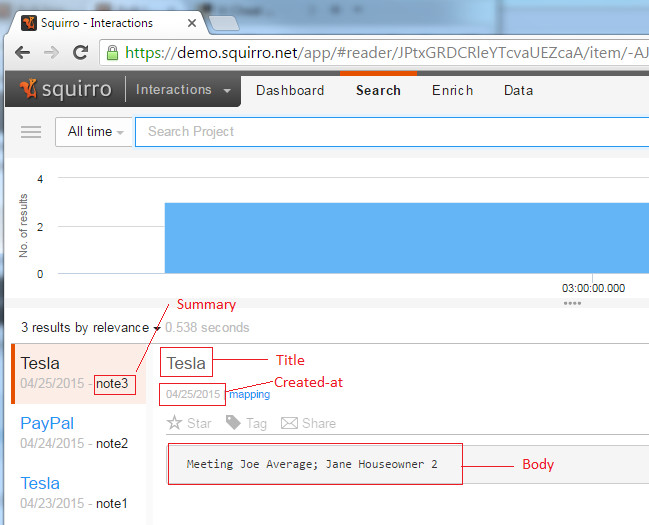
Simple usage and flow control
...
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--db-connection %db_connection% ^
--source-name db_source ^
--source-type database ^
--map-title InteractionSubject ^
--input-file interaction.sql |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
| Code Block | ||||||
|---|---|---|---|---|---|---|
| ||||||
SELECT * FROM Interaction_test WHERE InteractionSubject = 'Tesla' |
...
In Squirro, in the Data tab, you can see the result of the loads from the three different sources:
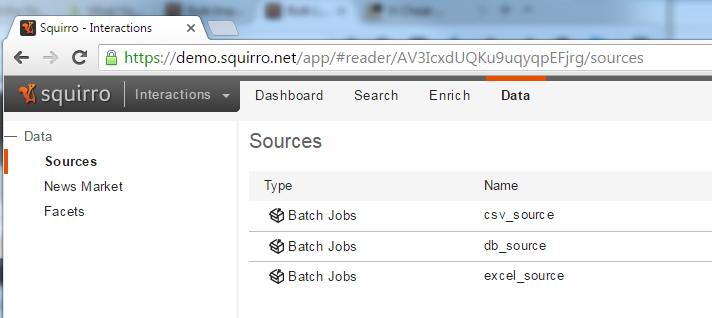
Database reset and incremental-column arguments
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--db-connection %db_connection% ^
--project-id %project_id% ^
--source-name db_source ^
--source-type database ^
--incremental-column Date ^
--map-title InteractionSubject ^
--input-file interaction.sql |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Another row was inserted in the meantime:
...
When re-executing incremental load, we should only have one row loaded into Squirro, the row that was just inserted in the database.
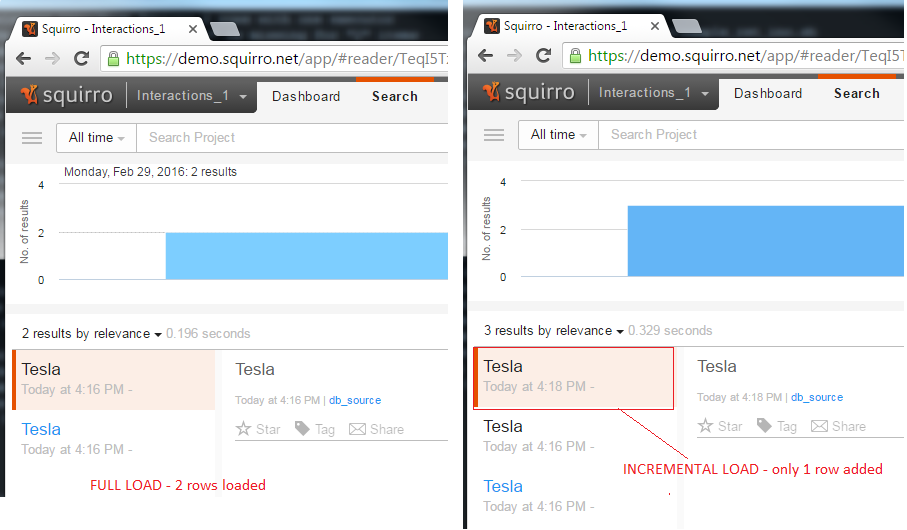
When using the --reset argument (together with the --incremental-column) the --incremental-column argument will be ignored and a full load will be performed, thus all three rows will be loaded:
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--db-connection %db_connection% ^
--project-id %project_id% ^
--source-name db_source ^
--source-type database ^
--incremental-column Date ^
--reset ^
--map-title InteractionSubject ^
--input-file interaction.sql |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
ItemUploader arguments: object-id, source-id, source-name, bulk-index, bulk-index-add-summary-from-body, batch-size
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--object-id 3rd8UDYpQwS8vvFoT3JVWA ^
--source-id yYPR8DA1SPyhTbEXIH0HYw ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv
|
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Usage for bulk-index, bulk-index-add-summary-from-body, batch-size
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name bulk_indexing_source ^
--source-type csv ^
--bulk-index ^
--bulk-index-add-summary-from-body ^
--batch-size 70 ^
--map-title InteractionSubject ^
--map-body Notes ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Parallel executors and source batch size arguments: parallel-uploaders, source-batch-size
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_source ^
--parallel-uploaders 5 ^
--source-batch-size 50 ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Metadata database related arguments
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_source ^
--meta-db-dir %meta_dir% ^
--meta-db-file %meta_file% ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Facets
In this chapter we will describe the use and functionality of the facets configuration file. The facets/keywords are used for filtering data in Squirro.
...
- default_value
- data_type
- input_format_string
- output_format_string
- delimiter
Attribute used for skipping columns:
...
You can find more information on these attributes in the Data Loader Facet Config Reference.
Below is a basic example for the facets configuration file and the mapping between the source field and the facet names. We will add attributes to the file as we describe more and more functionality. The “name” attribute is the one that identifies a facet in Squirro and not the key of each facet dictionary, unless the “name” attribute is missing and then the facet is identified by the dictionary key. The key of each facet dictionary is in fact the field name from the data source.
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_interactions ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv ^
--facets-file config/sample_facets.json |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
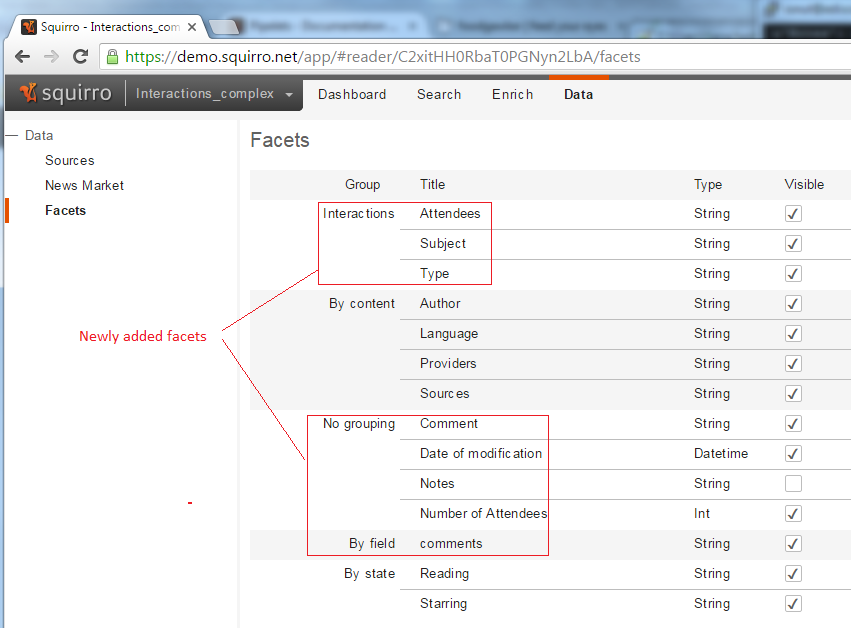
You can find the loaded facets in the Data >> Facets tab. You can see below the Facets tab before loading and after:
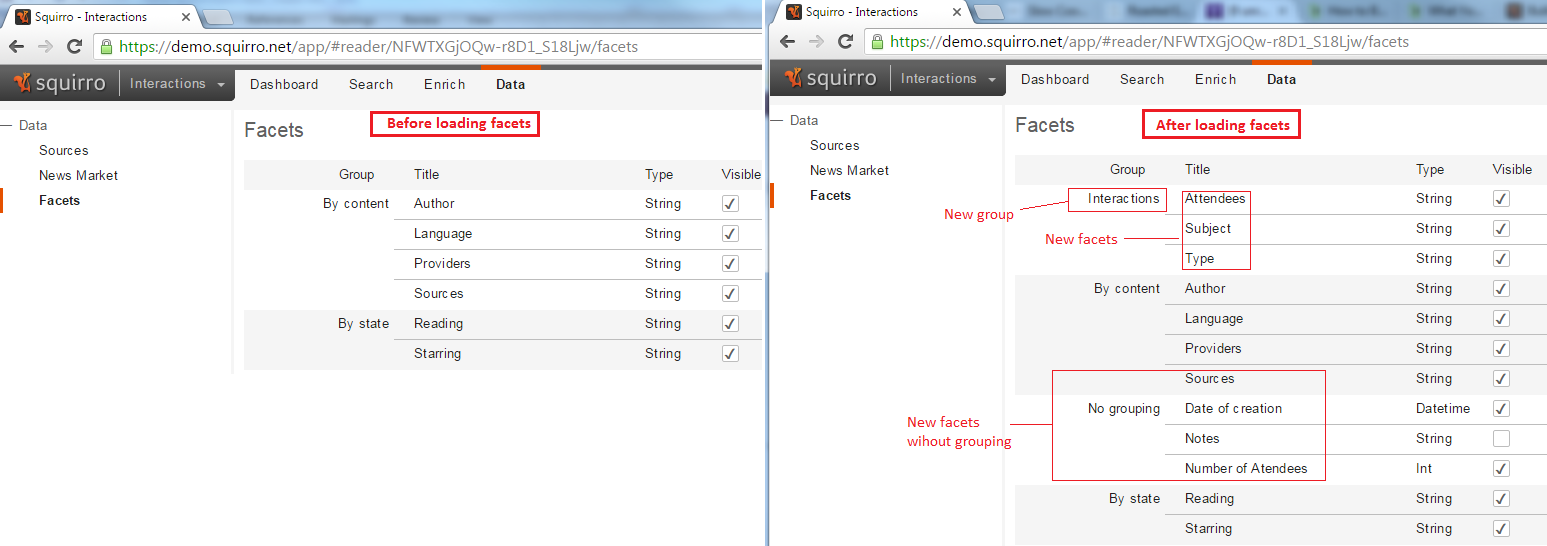
You can also see the new facets in the Search tab. Notice that the name of the selected facet is ‘Subject’ - the “display_name” attribute of the facet - coming from the "InteractionSubject" field in the data source which is the key of the facet dictionary. And the 2 distinct values of the subject field are shown: ‘Tesla’ and ‘PayPal’.
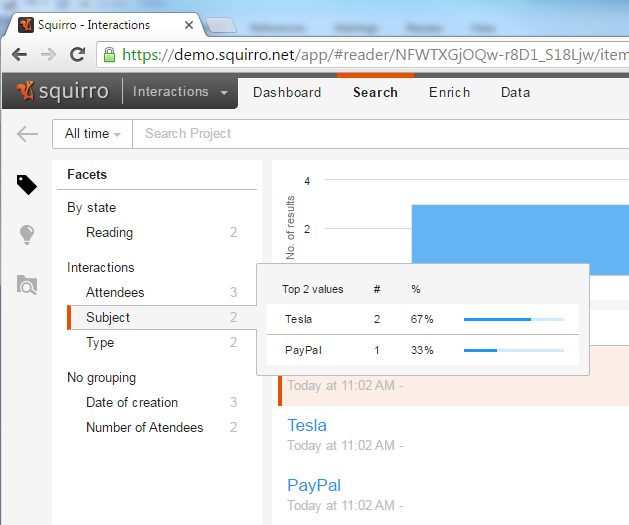
Data formatting
You may have noticed the formatting on the datetime data type with the "input_format_string" but there is even more formatting. The attributes attribute "input_format_string" and "output_format_string" are is applied to the data loaded into Squirro, more precisely to the date/datetime data types and the "format_instr" is applied on facet values in Squirro.
- input_format_string: is the format of the date/datetime strings coming from the source (used for csv and excel, the date values coming from the database are of type datetime and don’t need a format).output_format_string: is the format of dates expected by Squirro. Keep the default if this param is not supplied. For the moment, the only accepted format is the Squirro date format '%Y-%m-%dT%H:%M:%S'and excel, the date values coming from the database are of type datetime and don’t need a format).
- format_instr: this is the formatting instruction for the facet value display. This parameter defines how the Squirro UI will display the value. This is also relevant for int and float data types. It’s also documented here.
...
| Code Block | ||
|---|---|---|
| ||
"Date": {
"name": "Date of creation",
"data_type": "datetime",
"input_format_string": "%Y-%m-%dT%H:%M:%S",
"output_format_string": "%Y-%m-%dT%H:%M:%S",
"format_instr": "YYYY-MM-DD",
"visible": true
} |
Note that the "input_format_string" and "output_format_string" should should have a Python date format and "format_instr" is just generic date formatting.
...
From the Jinja templates, we have access to the source data using 3 variables:
| Variable Name | Type | Description | ||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| row | Python dictionary | Data as extracted from the source on format {key, value} key is the column name and value is the value of the key on one row Example accessing the value of a column:
| ||||||||||||||||||||||||||||||||||
| item | Python dictionary | State of the Squirro item after applying the mapping, data conversions and before pipelets. Example accessing a facet from the item:
| ||||||||||||||||||||||||||||||||||
| pivot_data | Python dictionary | Computed pivot data: If 2 tables are joined on a relation of 1 to n, the n rows are pivoted to generate only one line on the source. The pivot logic on the Data Loader recreates the rows from the joined table to use them in the Jinja template. The source extraction logic can be very complex and multiple joins with pivoted columns can be used. In order to differentiate columns from different the joins, the tool uses groups. if 2 columns are from the same group, it means that they were selected from the same joined table. Example: Source tables joined on InteractionID column:
Result is:
Data Loader pivot_data for the first line is:
|
The pivot columns are described using the facets configuration file. The attributes describing a column as pivotal are:
Example of usage in the template html file:
|
For this example we will use the CSV file again and we will format the body of the item using the --body-template-file argument.
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_interactions ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv ^
--facets-file config/sample_facets.json ^
--body-template-file template/template_body_interaction.html |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
Note: the name that we use for the facet in the “name” attribute in the facets config file has to be identical with the name from item.keywords tag in the template file
...
In Squirro, the items with pivoted columns will look like this:
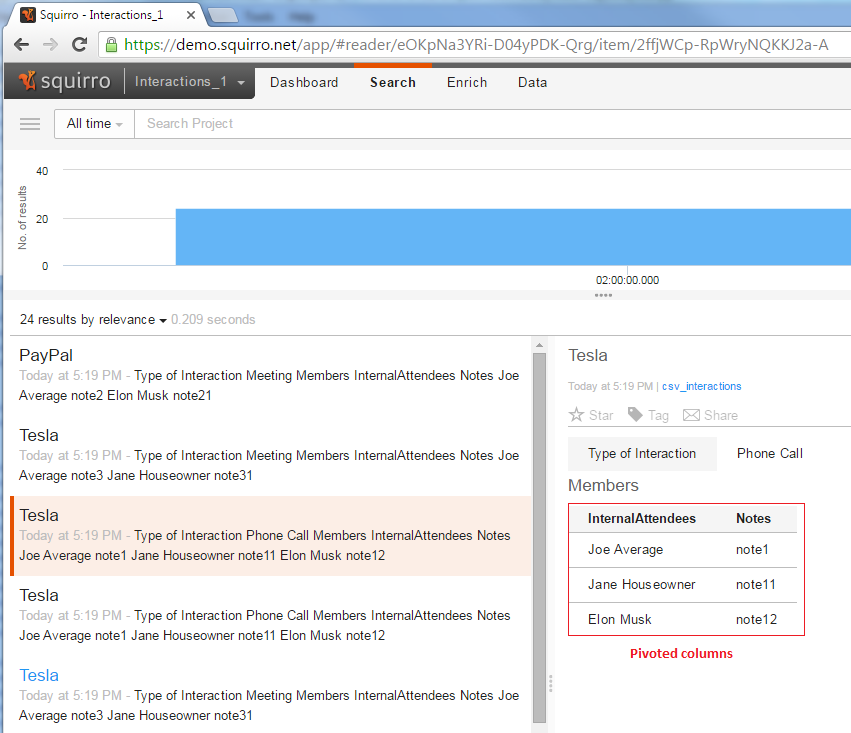
Pipelets
This data loader has the ability to run multiple pipelets before or after the templating step. The pipelets are external Python classes that are able to modify the Squirro item. The pipelets are instantiated once for each parallel process, but the code inside is executed once for each item (it is not recommended to open files in the consume method of the pipelet, you have to do it in init()).
The pipelets location, input arguments and execution order is described in a json file supplied as an argument for the loader script --pipelets-file. You can find more information on the attributes used in this file in the Data Loader Facet Config Reference. Also, the --pipelets-error-behavior specifies the jobs behaviour in case a pipelet rises an exception. By default is “error”. In case of error, the load will stop. The other option is "warning", which will only log the warning and continue the load.
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--source-name csv_interactions ^
--source-type csv ^
--map-title InteractionSubject ^
--source-file interaction.csv ^
--facets-file config/sample_facets.json ^
--body-template-file template/template_body_interaction.html ^
--pipelets-error-behavior error ^
--pipelets-file config/sample_pipelets.json |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
We will use the following pipelets config file:
...
The result of our simple pipelet is shown below:
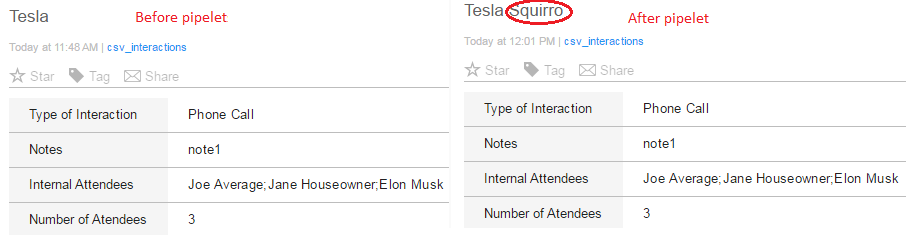
Complex job setup
You can find below a more complex example of a database load along with the configuration files, the template file, the python module and the command line parameters.
...
| Code Block | ||
|---|---|---|
| ||
squirro_data_load -v ^
--token %token% ^
--cluster %cluster% ^
--project-id %project_id% ^
--db-connection %db_connection% ^
--log-file log.txt ^
--parallel-uploaders 2 ^
--source-name db_interactions ^
--input-file interaction.sql ^
--source-type database ^
--source-batch-size 500 ^
--incremental-column DateModifiedOn ^
--map-title InteractionSubject ^
--map-id InteractionId ^
--map-created-at DateModifiedOn ^
--map-abstract InteractionType ^
--facets-file config/sample_facets.json ^
--body-template-file template/template_body_interaction.html ^
--pipelets-error-behavior error ^
--pipelets-file config/sample_pipelets.json ^
--meta-db-dir meta ^
--meta-db-file meta_interactions.db |
Note that the lines have been wrapped with the circumflex (^) at the end of each line. On Mac and Linux you will need to use backslash (\) instead.
The contents of the interactions.sql:
...
| Code Block | ||||
|---|---|---|---|---|
| ||||
{
"InteractionSubject": {
"name": "Interaction Subject",
"display_name": "Subject",
"group_name": "Interactions",
"visible": true,
"searchable":true
},
"InteractionType": {
"name": "Type of Interaction",
"display_name": "Type",
"group_name": "Interactions",
"visible": true,
"searchable":true
},
"DateModifiedOn": {
"name": "Date of modification",
"data_type": "datetime",
"input_format_string": "%m/%d/%Y %H:%M",
"output_format_string": "%Y-%m-%dT%H:%M:%S",
"format_instr": "YYYY-MM-DD",
"visible": true
},
"Notes": {
"name": "Notes",
"pivotal_group": "Members",
"delimiter": ";"
"visible": false,
"searchable":true
},
"InternalAttendees": {
"name": "Attendees",
"group_name": "Interactions"
"pivotal_group": "Members",
"delimiter": ";"
"visible": true
},
"NoAttendees": {
"name": "Number of Attendees",
"data_type": "int",
"visible": true
"searchable":false
},
"comments": {
"name": "Interaction comments",
"display_name": "Comment",
"data_type": "string",
"visible": true,
"searchable":true
},
"EntittledUsers": {
"name": "Users",
"auth": true
"auth_value_mandatory": true,
"import": false
},
}
|
...
The output in Squirrro:
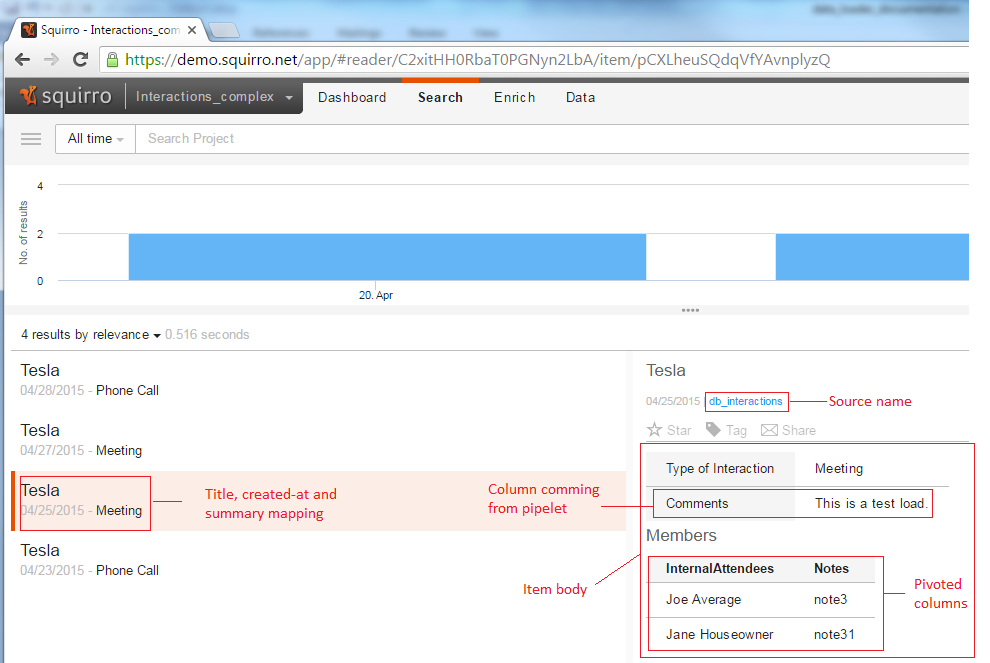
And the created facets:
And finally the contents of the log file, log.txt:
| Code Block | ||||
|---|---|---|---|---|
| ||||
2016-03-08 15:43:28,198 sq_data_load.py[12609] INFO Starting process (version 0.3.18). 2016-03-08 15:43:28,206 sq_data_load.py[12609] INFO Add module sample_pipelet.py to path 2016-03-08 15:43:28,206 sq_data_load.py[12609] INFO Start load from database 2016-03-08 15:43:28,825 sources.database INFO Execute initial load (full) for incremental processing 2016-03-08 15:43:32,319 sq_data_load.py[12609] INFO Start loading/deleting into/from Squirro 4 rows with 2 parallel executors 2016-03-08 15:43:33,072 sq_data_load.py[12609] WARNING One of the fields "link", "id" or "summary" is missing for "3" items 2016-03-08 15:43:33,075 sq_data_load.py[12609] INFO Intermediate number of rows loaded to Squirro: 3 2016-03-08 15:43:33,197 sq_data_load.py[12609] WARNING One of the fields "link", "id" or "summary" is missing for "1" items 2016-03-08 15:43:33,200 sq_data_load.py[12609] INFO Intermediate number of rows loaded to Squirro: 4 2016-03-08 15:43:33,238 sq_data_load.py[12609] INFO Total rows loaded to Squirro: 4 2016-03-08 15:43:33,240 sq_data_load.py[12609] INFO Last incremental value loaded to Squirro: 2015-04-28T16:58:00 2016-03-08 15:43:33,302 sq_data_load.py[12609] INFO Total run time: 0:00:05.108269 |
...