This document aims to outline how Squirro can scale from a single, small development host to a massive multi-node cluster, ingesting millions of documents daily and serving thousand of users.
...
Squirro is built for both the cloud and for on-premise deployments. For this we chose a service oriented approach, where the service is provided not by a few monolithic processes, but a fleet of small, very focused services.
| Info |
|---|
In computing, microservices is a software architecture style in which complex applications are composed of small, independent processes communicating with each other using language-agnostic APIs. These services are small, highly decoupled and focus on doing a small task, facilitating a modular approach to system-building. |
...
Squirro is designed for horizontal scaling. For additional storage needs, resilience and performance additional hosts can be added. In this case, the Squirro cluster and storage nodes are usually split up on different servers.
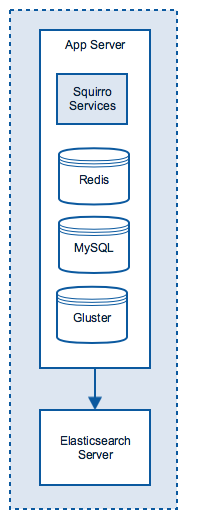
Initial Setup
To prepare for easy scaling, without yet investing in the full server farm, a Squirro setup can be split into the two roles from the beginning.
Recommended Cluster Setup
This is The full horizontal scaling, the recommended base setup looks as follows:

The nodes are operated in an active-active setup, the storage as well as the query load is shared across all hosts. Nodes can be added or removed with minimal or no downtime. We recommend a minimum of three nodes so that robust leader election is possible.
...
| Info | ||
|---|---|---|
| ||
Elasticsearch is a search server based on Lucene. It provides a distributed, multitenant-capable full-text search and analytics engine with a HTTP web interface and schema-free JSON documents. It is designed from the ground up to support massively distributed deployments with high-availability on commodity hardware. |
Squirro uses Elasticsearch as its primary means to store and query its documents. When you ingest data into Squirro, Elasticsearch is the component that will store the bulk of the data. Unless you index binary documents it is actually the only persistence component that will grow based on the data volume you ingest.
Thanks to Elasticsearch, Squirro can scale to massive sizes with relative ease, but there are still a few things to consider:
...
| Info | ||
|---|---|---|
| ||
MySQL is an open-source relational database management system (RDBMS); in July 2013, it was the world's second most widely used RDBMS, and the most widely used open-source client–server model RDBMS. ... MySQL is a popular choice of database for use in web applications, and is a central component of the widely used LAMP open-source web application software stack (and other "AMP" stacks). |
The MySQL RDBMS is used by Squirro to store configuration data.
No documents are stored in MySQL, hence it does not have to scale with the data volume ingested into Squirro. We've seen deployments with millions of documents and the MySQL database was less than 10 MB.
The main data stored in MySQL is:
- Users
- Groups
- Roles
- User Sessions / Auth Tokens
- Dashboards
- Smart Filters
- Saved Searches
- Scheduled Tasks / Alerts
Scaling
To achieve high availability and scalability the Squirro cluster service configures MySQL in a Master → Slave replication setup. Each node in the Squirro cluster can contribute a MySQL service to the cluster, and the cluster services uses Zookeeper to automatically elect a leader. All remaining nodes will become followers and replicate the entire database.
Read operations will be handled by all nodes, writes will go to the leader and replicated out to the followers.
There are two main concerns when scaling:
- Number of write operations to the Master node
- Concurrent Open Connections to any of the MySQL nodes. (each connection requires RAM)
In general pressure on MySQL is low and the caching layer and connection pooling improve the scaling capability further.
Redis
| Info | ||
|---|---|---|
| ||
Redis is a data structure server. It is open-source, networked, in-memory, and stores keys with optional durability. According to the monthly ranking by DB-Engines.com, Redis is the most popular key-value database. |
...
Redis is used by Squirro to provide an intelligent caching layer, both for the queries that are executed against Elasticsearch as well as for all HTTP requests between the various Squirro services. Cache entries can be stored long term, and get evicted intelligently when changes to the underlying data or the configuration occur.
Scaling
To achieve high availability and scalability the Squirro cluster service configures Redis in a Master → Slave replication setup. Each node in the Squirro cluster can contribute a Redis service to the cluster, and the cluster services uses Zookeeper to automatically elect a leader. All remaining nodes will become followers and replicate the entire database.
Read operations will be handled by all nodes, writes will go to the leader and will be replicated out to the followers.
There are two main concerns when scaling:
- Number of write operations to the Master node (but Redis is extremely fast)
- The latency between the master node and the slaves.
- The amount of RAM needed (Redis keeps all data in memory)
GlusterFS
| Info | ||
|---|---|---|
| ||
The GlusterFS architecture aggregates compute, storage, and I/O resources into a global namespace. ... Capacity is scaled by adding additional nodes or adding additional storage to each node. Performance is increased by deploying storage among more nodes. High availability is achieved by replicating data n-way between nodes. |
...
| Info | ||
|---|---|---|
| ||
Apache ZooKeeper is a software project of the Apache Software Foundation, providing an open source distributed configuration service, synchronization service, and naming registry for large distributed systems. ZooKeeper was a sub-project of Hadoop but is now a top-level project in its own right. ZooKeeper's architecture supports high availability through redundant services. |
Zookeeper is used by Squirro for leader election. Its design is perfect for this purpose and helps Squirro detect and handle network segmentation / split brain events.
...